Diffusion vs Transformer for Video Generation: Which Is Better for Real-World Results?
If you are choosing an AI video stack in 2026, the real question is not which architecture wins in theory, but which one gives you the best mix of quality, speed, scale, and workflow fit.
Diffusion vs transformer video generation: the core difference that matters in practice

How diffusion generates video frames
Diffusion models generate video by starting from noise and repeatedly denoising it into something structured. In practice, that means the model does not jump straight to a final clip. It refines the result step by step, which is why diffusion is so often linked with strong visual quality in current video tools. If your top priority is rich texture, realistic lighting, cleaner faces, and frames that feel cinematic, this iterative denoising process is a big reason diffusion-based systems keep showing up at the top of real-world quality tests.
For production work, the practical implication is clear: diffusion tends to reward patience and compute. More steps can improve fidelity, but they also increase generation time. That matters when you are doing shot exploration, client reviews, or batch renders. If you only need a few premium clips, diffusion can be a great fit. If you need thousands of outputs on a deadline, the cost of repeated denoising can become the bottleneck.
How transformers model video as sequences
Transformers approach video more like sequence modeling. Instead of focusing on denoising a frame from noise over many iterations, they treat video as a structured series of tokens, patches, or latent units across time. That makes them naturally attractive for handling longer temporal relationships, prompt-conditioned structure, and coherence across many frames. If you care about what happens in second 1 affecting second 8, transformers have an intuitive advantage because sequence dependency is exactly what they were built to model well.
This is also where the scaling argument matters. One research note highlights a common ML view that scaling laws diverge here: transformers tend to follow data and parameter scaling more cleanly, while diffusion can be bottlenecked by iterative generation. For teams planning larger datasets, bigger training runs, or long-term roadmap efficiency, that is not a small detail. It affects training strategy, serving economics, and how much headroom you may get by adding more data and compute.
Why many modern systems combine both approaches
The reason diffusion vs transformer video generation is no longer a clean binary is that modern systems increasingly blend the two. Recent research discussions point to diffusion transformers and latent diffusion transformer approaches for video, including work such as Latte. There is also optimization-focused work around transformer-based diffusion models for video, including techniques relevant to Adobe Firefly video generation performance. That tells you where the field is going: not toward purity, but toward practical hybrids.
So when you compare stacks, do not assume one architecture should dominate every benchmark. There is no universal winner because the best choice changes with use case, compute budget, latency targets, output style, and editing workflow. A solo creator making premium image-to-video ads may prefer diffusion-first systems. A platform team optimizing throughput and temporal structure may lean transformer-heavy. A lot of the strongest pipelines now sit in the middle, using transformers for sequence intelligence and diffusion for final visual quality.
When diffusion video generation is the better choice
Best use cases for diffusion-first video models
Diffusion-first video models are usually the right call when your buyers, viewers, or internal reviewers judge the output mainly by how good it looks. That includes cinematic shots, ad creatives, stylized sequences, beauty close-ups, product glam shots, mood-heavy visuals, and premium image-to-video workflows. When you have a hero frame or reference image and want the final motion clip to preserve texture, atmosphere, and visual richness, diffusion still feels like the safer bet in many real production cases.
That tracks with how people actually talk about current tools. Across discussion sources, diffusion-based systems are widely associated with high-quality generation and realism. One Reddit commenter even said, “Nothing beats diffusion for getting good images and audio.” That is an opinion, not a benchmark, but it reflects a very common practitioner instinct: if the clip must look expensive, diffusion is often where people start testing first.
Why diffusion is often preferred for visual fidelity
The visual edge comes from the denoising process itself. Because diffusion refines the output gradually, it often handles fine detail, texture transitions, and image-level realism especially well. If your current pain point is muddy frames, weird skin, unstable lighting, or scenes that feel synthetic, a diffusion-first model can often reduce that. It is also very strong for stylized output because the stepwise process tends to preserve nuanced appearance cues that matter in fashion, fantasy, anime-inspired scenes, and branded art direction.
For practical evaluation, test diffusion when your acceptance criteria include frame grabs that must stand on their own as good images. Pull stills from second 2, 4, and 6 and inspect them the way you would inspect a campaign visual. If those stills matter as much as the motion itself, diffusion is a strong candidate. This is especially true for image to video open source model experiments, where creators often care deeply about preserving the look of the source frame.
Where cascaded diffusion helps
Cascaded diffusion models are worth special attention because they split denoising into multiple stages, with each stage handled by a separate model. Instead of one monolithic process, you can have specialized phases for structure, detail, or resolution. That gives you finer control over quality and can make a workflow easier to tune for specific goals.
In practice, cascaded diffusion helps when you need to separate “get the motion and composition right” from “make it beautiful.” You can generate a lower-resolution or simpler base clip, then refine in later stages for detail and finish. That makes diffusion a strong fit for quality-first creative production where you are willing to trade some speed for more control.
If I were choosing diffusion today, I would prioritize it for four situations: cinematic shot generation, stylized outputs with a strong visual identity, image-to-video workflows built around a hero still, and any production where the final bar is “would I ship this as premium creative?” In those lanes, diffusion remains one of the most reliable ways to get high-end visual results.
When transformer video generation is the better choice
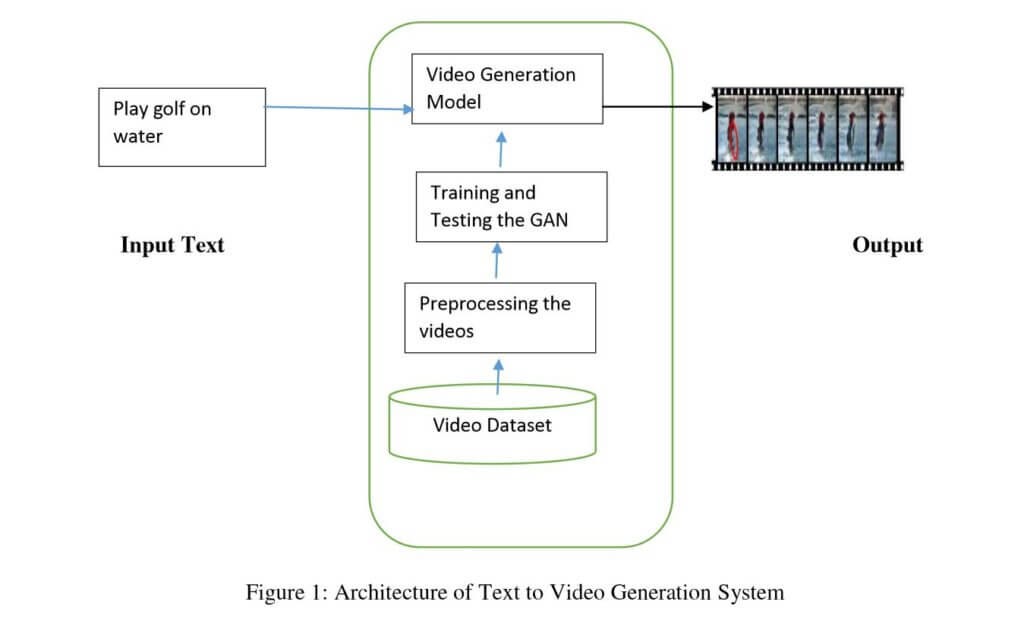
Why transformers appeal to teams thinking about scaling
Transformers become very attractive when the conversation shifts from “best single clip” to “best system at scale.” A key research note here is the scaling-law argument: transformers tend to follow data and parameter scaling more cleanly than diffusion, while diffusion is bottlenecked by iterative denoising. That matters if you are planning for bigger training corpora, longer context windows, more product surfaces, or a roadmap where the model needs to improve predictably as you add data and compute.
If your team is building a pipeline rather than just selecting a creator tool, that cleaner scaling story is powerful. It can shape how you invest in infrastructure, how you estimate future quality improvements, and how you choose between short-term quality and long-term platform economics.
Sequence modeling advantages for video generation
Video is sequence by nature, and this is where transformers often feel architecturally aligned with the problem. They are good at modeling temporal relationships, maintaining structure over multiple frames, and handling longer contexts. If your clips are failing because characters drift, camera movement loses intent, or object interactions break down across time, transformer-led systems deserve serious testing.
This is especially relevant for structured outputs: tutorials, product demos, repetitive action sequences, storyboard-like generation, or any task where consistency across many frames matters more than having the single prettiest frame. A transformer can be a better fit when you need coherence and progression, not just visual richness.
That is also why an open source transformer video model can be attractive for technical teams who want to experiment with sequence behavior directly. If you are evaluating something niche, even a search phrase like happyhorse 1.0 ai video generation model open source transformer reflects the kind of specific architecture-driven hunting people do when they want sequence-centric experiments rather than just polished outputs.
How deployment economics can favor transformer-heavy systems
Serving cost is where transformers often gain practical momentum. Diffusion’s iterative generation can slow inference and reduce throughput, especially in production settings where many users are requesting clips at once. If every render needs many denoising steps, latency and compute costs can escalate quickly. That can make diffusion expensive to serve, even when the output quality is excellent.
Transformer-heavy systems can be easier to justify when the business model depends on faster iteration, higher request volume, or lower average cost per generated clip. If your product needs many previews, rapid prompt-response loops, or internal batch generation at scale, speed matters almost as much as raw quality.
That makes transformers a smart choice for enterprise pipelines, larger datasets, and roadmap planning around scalability. If you are building a generation engine that must grow over time, support multiple teams, and remain economically viable under heavier load, transformer-led systems often deserve priority on the shortlist.
Diffusion vs transformer video generation for quality, speed, cost, and control
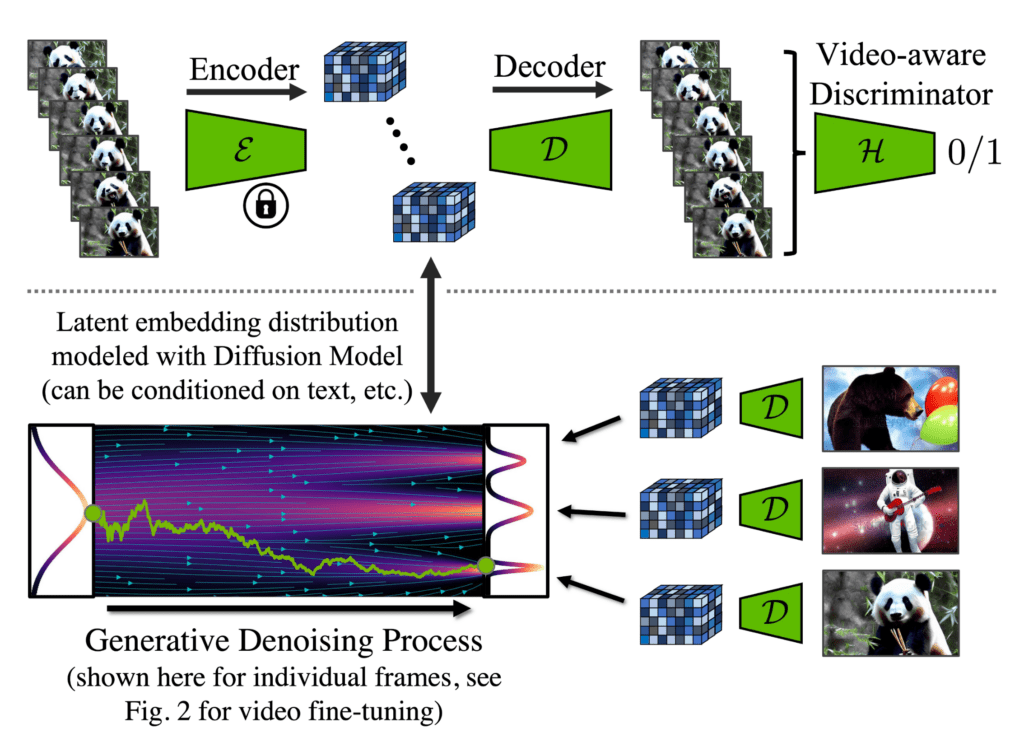
Visual realism and consistency
For most buyers, the first comparison is simple: which system gives the best-looking usable video? Right now, diffusion is still frequently associated with stronger image quality and realism, while transformers are often discussed as stronger on scaling and sequence efficiency. In real testing, that often shows up as a tradeoff between prettier individual frames and cleaner long-range temporal structure.
When comparing diffusion vs transformer video generation, do not score only on the first wow moment. Score on realism across the whole clip. Check faces, hands, fabric, reflections, and fine textures, but also verify whether the subject remains coherent from start to finish. A model that produces one beautiful second and then degrades is less useful than one that stays consistent for the full shot.
Inference speed and iteration time
Speed changes the whole workflow. Diffusion often takes longer because generation is iterative, and that affects both creator experience and business cost. If you are refining prompts quickly, making many variants, or producing short-form assets in volume, slower inference can quietly kill momentum. Even if the clip quality is higher, the time to get five test renders may be too high for your pipeline.
Transformers can be attractive when you need shorter iteration cycles. Faster previews mean more prompt experiments, quicker editor handoff, and less idle time waiting for renders. This matters a lot for social content, performance marketing, and internal prototyping. It also matters if you need to run AI video model locally, because local hardware constraints make inefficient inference much more painful.
Cost, accessibility, and local/open-source options
Architecture is only part of the buying decision. Platform pricing often matters more. One useful data point from the research notes: OpenArt can be used for $14 and gives access to popular models. That is a strong reminder that architecture choice is often mediated by access layers. A creator may end up using diffusion or transformer-backed models not because of deep architectural loyalty, but because a low-cost platform makes experimentation easy.
For open workflows, this is where keywords like open source ai video generation model, open source transformer video model, and image to video open source model become practical buying filters rather than SEO jargon. You may want an open model because you need local deployment, custom fine-tuning, lower ongoing cost, or fewer platform restrictions. But check the license carefully. Open source ai model license commercial use is still a critical filter, especially if the output will support paid campaigns, client work, or product features.
A good cost-control process is to estimate total cost per usable clip, not cost per generation. Include failed generations, reruns, upscale passes, edit time, and review cycles. Diffusion may cost more per attempt but deliver more premium winners. Transformer-led systems may be cheaper and faster over many iterations. For budget experimentation, hosted platforms can be the fastest way to test both. For tighter control, local or open-source options may win, as long as the license and hardware demands match your use case.
Best tools and model types to test in diffusion vs transformer video generation

Commercial tools worth comparing
The smartest way to compare tools in 2026 is not to assume architecture equals outcome. One source behind a “Best AI Video Generators in 2026” roundup claims more than 1,000 videos were generated across every major AI model to identify the strongest performers. That is exactly the right mindset: test outputs empirically across tools, because real-world performance often depends on the total pipeline, not the label on the architecture.
A strong commercial benchmark to include is Google’s Veo 3.1. It has been described as the best AI video generation all-arounder on the market and is specifically noted as useful for generating highlights and clips for short-form posting. If your workflow includes social edits, promos, teaser reels, or reusable visual snippets, Veo 3.1 belongs on the shortlist even before you decide whether you are philosophically more diffusion-leaning or transformer-leaning.
Open-source and multi-model platforms
For broader comparison, multi-model platforms are extremely useful because they reduce switching friction. Tagshop AI is a good example from the research notes, offering multiple models including Nano Banana 2, Nano Banana Pro, Seedream 4.5, and Seedance. That kind of setup is ideal when you want to compare prompt behavior, motion style, and generation speed without rebuilding your workflow every time.
If your goal is open experimentation, search intentionally for an open source ai video generation model that matches your delivery needs. If you need local control, prioritize whether you can run ai video model locally on available GPUs. If your use case is sequence-heavy, compare at least one open source transformer video model. If your workflow starts with stills, make sure your shortlist includes an image to video open source model rather than only text-to-video tools.
How to build a fair test shortlist
A fair shortlist should compare six things: output realism, prompt adherence, motion coherence, generation time, editability, and total cost per usable clip. Run the same prompts across all tools. Use one cinematic prompt, one product prompt, one human motion prompt, and one image-to-video test. Export results at the same duration and inspect them side by side.
For each model, score how often the clip is actually usable without heavy repair. That is more important than headline quality. Also note whether the output survives editing. Some clips look great alone but fall apart when trimmed, upscaled, color-matched, or combined into a sequence.
This is the practical heart of diffusion vs transformer video generation: what survives contact with your workflow. Test the architecture through tools, not just theories. A hybrid model on a well-tuned platform may beat a pure diffusion or pure transformer system simply because it gives better outputs faster at a cost you can sustain.
How to choose between diffusion, transformer, and hybrid video generation models
A simple decision framework
Start with the job, not the architecture. If the main goal is quality-first creative output, start diffusion-first. If the goal is short-form social clips with fast iteration, compare strong commercial all-arounders and efficient hybrids. If the goal is a scalable production pipeline, put transformer-led and hybrid systems at the front of the queue. If the goal is research experimentation, include open and local options so you can inspect behavior directly.
A simple decision tree works well:
- Need the best-looking cinematic or stylized output? Start with diffusion or cascaded diffusion.
- Need short clips for highlights, promos, and social posting? Test Veo 3.1 and multi-model tools first.
- Need scalable generation for enterprise workflows? Prioritize transformer-led systems and optimized hybrids.
- Need architecture-level experimentation? Test an open source ai video generation model, an open source transformer video model, and a hybrid baseline side by side.
Best architecture by use case
Diffusion is usually strongest for premium creative, image-led workflows, and visual polish. Transformers make sense for larger datasets, sequence-heavy generation, and deployment plans where throughput matters. Hybrids increasingly cover the middle ground, which is why they are becoming the practical default.
That hybrid trend is hard to ignore. Recent video research keeps pointing to transformer-based diffusion and latent diffusion transformer approaches, showing that many strong systems now borrow from both camps. Production optimization work matters too. Efforts tied to Adobe Firefly video generation show that tuning transformer-based diffusion models for deployment is an active area, which means raw architecture matters less than how well the stack is optimized.
Questions to ask before committing to a stack
Before you commit, run through a short checklist:
- What is your compute budget for both testing and production?
- How much latency can your workflow tolerate?
- Is the quality bar “good enough” or “premium creative”?
- Do you need an open source ai model license commercial use approved for paid work?
- Do you need to run ai video model locally for privacy, customization, or cost control?
- Will your dataset and product likely scale significantly over the next year?
- Are you doing text-to-video, image-to-video, or both?
- Do you need easy editability after generation?
The best answer is usually use-case specific. If you only ask which architecture is theoretically superior, you miss the real constraint set. The strongest practical stacks in 2026 are often hybrids because they balance quality, temporal structure, and deployment efficiency better than a rigid one-side-only approach.
Conclusion

The real answer to diffusion vs transformer video generation is almost never a universal winner. Diffusion remains a strong choice when visual fidelity, realism, and quality-first creative output are the priority. Transformers make a lot of sense when you care about scaling, long-range sequence modeling, throughput, and deployment economics. Hybrids are increasingly the sweet spot because they combine transformer strengths in structure and scaling with diffusion strengths in final visual quality.
If you are choosing a stack right now, test based on your workflow: cinematic shots, short-form clip generation, enterprise-scale production, or open-source experimentation. Use concrete comparisons, track total cost per usable clip, verify license terms for commercial use, and shortlist tools that match the way you actually ship work. In practice, the best stack is the one that produces the highest percentage of usable videos at the quality, speed, and cost your pipeline can support.