HappyHorse GitHub Repository: Verified Status, Safe Checks, and Expected Code Content
If you are searching for happyhorse github repo code, the fastest way to save hours is to separate verified public facts from recycled hype. Right now, the useful reality is simple: the official project is still described as coming soon in multiple research sources, and there is no confirmed official repository you can safely clone for production, benchmarking, or local setup. That means the smartest move today is not hunting random forks, but learning how to verify ownership, spot placeholder repos, and prepare a checklist for the moment a real release lands.
What the happyhorse github repo code status is right now
Official repository status
The current verified status is straightforward: the official HappyHorse GitHub repository has not been publicly verified yet. Across the research set, the same pattern keeps showing up. The WaveSpeedAI Blog post Is HappyHorse-1.0 Open Source? What We Can Verify reports that the HappyHorse site’s GitHub link says “coming soon,” and that there is no public repository with code or a usable README. A second source, Where to Try HappyHorse-1.0: Access and Availability, says both the GitHub repository and Model Hub are listed as “coming soon” and appear to be placeholders rather than live release pages.
That matters because it changes the answer from “hard to find” to “not officially published yet.” If you expected a hidden repo, a private beta link, or an under-indexed release page, the research does not support that. The best verified reading is that the official release has not happened publicly.
What is publicly verified
What is verified today is mostly negative confirmation, but it is still actionable. The research notes state that no verified official model assets or inference code were identified. The source Happy Horse 1.0 — AI Video Generator Information Collection explicitly says Happy Horse 1.0 has not yet been officially open-sourced, with no model weights, no inference code, and no official GitHub repository available.
A third source, HappyHorse model decryption: A complete analysis..., says that as of early April 2026, the official page still listed GitHub and Model Hub as “Coming Soon.” That timestamp matters because it rules out the common assumption that maybe the repo appeared briefly and got moved. Based on the research material, the public-facing status still looked unreleased into April 2026.
What is not available yet
Here is the quick answer you can use immediately: there is currently no confirmed official repo to clone for production or local testing.
More specifically, no verified official model weights have been identified. No verified inference scripts have been identified. No official README with installation or usage steps has been identified. No runnable setup, dependency file set, or checkpoint download path has been verified in the supplied materials. The official GitHub and Model Hub links are reported as placeholders, not active release destinations.
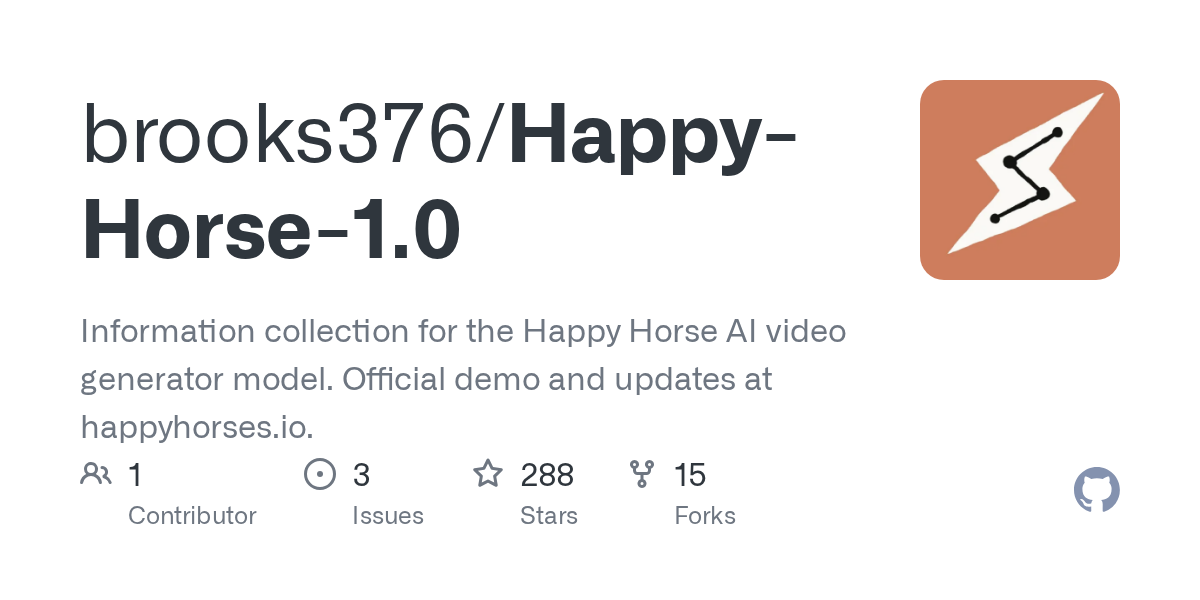
There is one public GitHub repository mentioned in the research: brooks376/Happy-Horse-1.0. But the title and snippet describe it as an “Information collection” repo pointing users to happyhorses.io for updates, not as a full model release. There is also a GitHub issue titled Fake Repo · Issue #3 · brooks376/Happy-Horse-1.0 that alleges the repository is fake, AI-generated, misleading, and used for star-farming or traffic hijacking. That allegation is not independently proven in the research notes, so it should be treated as a warning signal rather than a final verdict. Still, it is enough to avoid assuming that a project-name match equals authenticity.
If your goal is to find happyhorse github repo code you can run locally today, the evidence says stop there: no verified official release is public yet.
How to verify whether a happyhorse github repo code page is official
Fast trust checks before downloading
Before you download anything, start with the ownership trail. Open the official HappyHorse project site first and look for a direct GitHub link that resolves to a real repository under a clearly identified owner. If the site still shows “coming soon,” treat every public repo using the HappyHorse name as unverified until proven otherwise. Then check whether the same repository is linked from the project’s official social accounts, release notes, or model hosting page. A real release usually appears in more than one official place on the same day.
Next, inspect the repository page itself. A legitimate release usually has a clear README, installation steps, dependency files such as requirements.txt, environment.yml, pyproject.toml, or Dockerfile, and at least one usage example. For a video model, you should also expect inference instructions, hardware requirements, and links to checkpoints or model cards. If a repo has a flashy title but no reproducible setup path, treat it as informational at best.
Signals that a repo may be unofficial
The clearest warning sign in the current research is the brooks376/Happy-Horse-1.0 example. The repository is described as an “Information collection for the Happy Horse AI video generator model. Official demo and updates at happyhorses.io.” That wording alone is not what a full model release looks like. It sounds like a tracking page or aggregator, not a runnable implementation.
Then there is the GitHub issue alleging it is a fake or misleading repo. Even though that claim is not independently confirmed in the research notes, it shows exactly why you should not assume a project is official just because it uses the project name. Name matching is easy. Ownership matching is what counts.
Other red flags are practical. Weak or generic README text, no release tags, no commit history showing real development, no dependency files, no model card links, and no explicit license should all slow you down. If a repo claims breakthrough model access but has no installation path, no sample outputs with reproducible commands, and no explanation of supported tasks, that is a major trust gap.
Safe verification workflow
Use a simple workflow every time. Step one: confirm the repository is linked from the official HappyHorse site. Step two: confirm the same repository appears in an official announcement thread, release note, or trusted social account. Step three: verify that the maintainer identity matches the official project identity, not just a similarly named user account.
Step four: audit the repo structure before downloading. Check the README for exact setup commands, Python or CUDA versions, model download instructions, and supported inference modes. Check tags and releases to see whether there is a proper versioned launch. Check the issue tracker for bug reports, maintainer responses, and launch-day clarification. Check commit history for sustained development rather than a single bulk dump. Check the license so you know whether personal use, research use, or commercial use is allowed.
Step five: do not run code until ownership and announcement trails line up. That means no blind cloning, no executing shell scripts from a fresh repo, and no pulling model files from third-party mirrors unless the official release directly references them.
If you stay disciplined on those checks, you avoid the two biggest time sinks: testing a nonfunctional placeholder and exposing your machine to unknown code.
What readers should expect inside the happyhorse github repo code when it finally launches
Files likely to appear in an official release
When the real release arrives, the structure should look familiar if you have used any serious open source ai video generation model repo before. Start with a README that explains what the model does, what tasks are supported, how to install dependencies, and how to run inference. You should also expect an environment definition such as requirements.txt, environment.yml, pyproject.toml, or a Docker setup. If the repo is usable, there should be clear inference entry points like infer.py, predict.py, notebook demos, or command-line examples.
A trustworthy release should also include sample prompts, example inputs, expected output formats, and either direct checkpoints or official download links to a model hub. If weights are too large or hosted elsewhere, the repository should tell you exactly where to get them and how to place them in the expected directory structure. License terms should be visible at the root of the project, not hidden in a side document.
What usable inference code usually includes
Usable code is different from an info page. A functional repo normally includes script arguments, config files, and at least one reproducible command. For an image to video open source model, that often means a script that accepts an input image, prompt text, frame count, resolution, seed, guidance settings, and output path. For a text-to-video or broader open source transformer video model, you should expect task-specific examples and notes on memory usage, batch limits, and generation speed.
Documentation around hardware is just as important. A proper release should say whether it supports single-GPU inference, multi-GPU inference, CPU fallback, quantized paths, or lower-VRAM modes. It should also list CUDA, Python, and library version expectations. If you want to run ai video model locally, these details are what turn a repository from interesting to actually usable.
What a complete open-source release should provide
The easiest way to tell whether the launch is real is to ask one question: is this a functioning code release, or just an information collection repo?
An information collection repo may contain links, screenshots, notes, benchmark claims, or summaries of the model. That can be useful for tracking updates, but it is not the same as runnable source. A real release should provide enough material to install dependencies, fetch weights, execute inference, and reproduce at least a baseline result. Without those pieces, the repo is not a working release no matter how strong the branding looks.
Build a quick checklist for launch day. Look for:
- A root README with install and usage steps
- Environment or dependency files
- Inference scripts or notebooks
- Sample prompts and expected outputs
- Checkpoints or official weight links
- License terms
- Hardware requirements
- Supported tasks like image-to-video, text-to-video, or editing workflows
If several of those are missing, you are probably looking at a placeholder, mirror, or unofficial wrapper rather than the true happyhorse github repo code release.
How to track the real happyhorse github repo code release without missing updates
Where to monitor first
The best first stop is the official HappyHorse website. The research consistently points back to the official site as the place where GitHub and Model Hub links are referenced, even if they currently show “coming soon.” That makes the site the primary source for a real release. If the official repo launches, the cleanest signal should be a live, non-placeholder link there.
After that, monitor the project’s official social accounts and any official model hosting pages. A proper launch usually gets mirrored across those channels quickly, especially for a high-interest video model. If the site updates but no social account or model hosting page acknowledges it, pause and verify before you download anything.
What alerts to set up
Use a few lightweight alerts so you do not have to manually check every day. Save GitHub searches for “HappyHorse” and “Happy-Horse-1.0,” then sort by most recently updated. Set repository watch alerts if an official account appears. Use RSS or page-change monitoring on the official site page where the GitHub and Model Hub links are listed. Turn on notifications for official social posts if the project has public channels.
You can also watch likely model hosting destinations. If a Model Hub page is expected, set a watchlist for the project name there as well. This is especially useful for anyone tracking the happyhorse 1.0 ai video generation model open source transformer angle, because weights and model cards often appear on a hosting platform alongside or shortly after a GitHub launch.
How to confirm a launch announcement
The safest confirmation pattern is simultaneous updates across three places: the official site, the repository page, and the model hosting page. If all three align on the same owner name, version, and release notes, that is strong evidence the launch is real. If only one element appears and the others stay unchanged, hold off.
Keep a short release-day checklist ready:
- Verify repository ownership
- Read the license before downloading weights
- Inspect install docs and hardware notes
- Review issue activity for immediate bug reports
- Test only in a safe isolated environment
That workflow is quick, and it prevents the usual launch-day mistakes. With high-interest repos, mirrors, forks, and scraped copies can appear fast. Confirm first, clone second.
Best alternatives while happyhorse github repo code is still unavailable
Open source AI video generation model options
Since there is no verified official HappyHorse release yet, the practical move is to work with tools that are already public and testable. Focus on an open source ai video generation model with a verified repository, active maintainers, and documented inference steps. Those three signals matter more than launch buzz. If you can clone it, install it, and reproduce sample output from a maintained repo, it is already ahead of an unconfirmed release.
For comparison, prioritize projects with recent commits, issue responses, release tags, and clear hardware guidance. If a repo explains VRAM tiers, CUDA versions, and common failure points, it will save you far more time than a model with big claims and no docs.
Image to video open source model choices
If your main interest is image-to-video, narrow your search to an image to video open source model that already documents input handling, temporal consistency settings, frame controls, and resolution constraints. Repos in this category are easier to evaluate because the workflow is concrete: provide an image, set generation parameters, and render a clip. You can compare output quality, speed, memory usage, and prompt responsiveness directly.
This is also where the search intent around open source transformer video model becomes useful. Some projects emphasize transformer-based generation and research novelty, while others emphasize practical local inference. If your goal is experimentation on your own hardware, practical inference quality and setup clarity usually matter more than architecture branding alone.
How to compare alternatives for local runs
When you want to run ai video model locally, compare five things first: supported tasks, inference difficulty, hardware needs, documentation quality, and community support. Supported tasks tell you whether the model does image-to-video, text-to-video, editing, interpolation, or conditioning workflows. Inference difficulty tells you whether setup is a one-command install or a weekend of dependency repair. Hardware needs decide whether you can run it on your current GPU. Documentation quality determines how quickly you can debug. Community support shows whether anyone is around when things break.
Licensing belongs in this comparison too. Check whether the project has transparent terms for code, weights, and output. If the repo is silent or vague, assume nothing about reuse rights.
While waiting for HappyHorse, the strongest alternatives are the ones that are verifiable right now: real code, clear docs, visible maintainers, and a license you can actually read. That combination beats speculation every time.
License, local setup, and safety checks before using any happyhorse github repo code download

Open source AI model license commercial use basics
When a repo finally appears, do not assume “open source” automatically means unrestricted commercial use. For AI projects, code and model weights may have different licenses, and generated output can have separate usage conditions or policy restrictions. That is why open source ai model license commercial use questions need to be answered from the actual repository documents, not from summaries on social posts.
Check three things separately: the code license, the weight license, and any acceptable-use policy. A permissive code license does not guarantee the weights are commercially usable. A research-only weight license can block production use even if the GitHub repo itself looks open. If generated output terms are mentioned, read those too, especially if you plan to ship content commercially or offer a service built on the model.
Local environment precautions
Use an isolated environment before running anything from a newly released repo. A fresh virtual environment, conda env, container, or disposable machine is the safe baseline. Review the dependency files before installation so you know what is being pulled in. If the setup script downloads remote assets, inspect the URLs first. If the repo asks you to execute shell scripts or binaries you do not recognize, pause and review them manually.
For GPU projects, check CUDA, driver, Python, and PyTorch version compatibility before you start. A true release should document those requirements clearly. It should also tell you the expected VRAM range, supported operating systems, and whether there are lower-memory inference paths.
What to inspect before running code
Before the first run, inspect the repository for:
- Dependency files and pinned versions
- Shell scripts that modify system settings
- Network calls that download assets from unknown locations
- Precompiled binaries or executables
- Post-install hooks
- License and usage restrictions
- Hardware requirements and tested configurations
Then scan the README for exact inference paths. A real release should say how to run text-to-video, image-to-video, or other supported tasks, and whether there are recommended defaults. If that information is absent, the repo is either incomplete or not intended as a production-ready release.
These checks save time as much as they reduce risk. High-interest repos tend to attract reposts, wrappers, and low-quality clones. If a claimed HappyHorse release appears before official confirmation, your safest move is to verify ownership, inspect the code structure, and test in a sandbox only after the trail is consistent.
Conclusion

Right now, the clearest verified position is that HappyHorse is not yet officially open-sourced in a public, runnable way. The research points to official GitHub and Model Hub links being marked “coming soon,” with no verified weights, inference code, README, or local setup available from an official source. Public repos using the name, including the reported brooks376/Happy-Horse-1.0 example, should not be treated as official just because they exist.
The practical path is simple: assume there is no confirmed official repo yet, verify every claimed release against the official site and announcement trail, and keep a launch checklist ready. When the real release lands, check ownership, license, install docs, issue activity, and hardware notes before running anything. Until then, use verified alternatives with active maintainers, clear setup instructions, and transparent licensing. That approach keeps you productive now and ready the moment the genuine HappyHorse code finally goes live.