Transformer Architecture for Video Generation: A Technical Guide
Modern video generation increasingly depends on transformer-based diffusion systems that can model spatial detail and temporal consistency at the same time. That shift happened fast: over roughly the last 2 to 3 years, video generation moved from short, unstable clips toward systems that can preserve identity, motion, and scene layout across much longer outputs. If you are evaluating modern generators, the key technical lens is no longer “is it a transformer or is it diffusion?” but “how is the transformer used inside the diffusion pipeline, and how efficiently does it handle space plus time?” That is where most of the real progress is happening.
What transformer architecture video generation means in practice

Why transformers matter for video, not just text
When people first learn transformers, they usually meet them through language models. The original Transformer, though, was introduced as an encoder-decoder architecture built around self-attention in both the encoder and decoder. That core idea still matters in video: instead of relying on recurrence or convolution alone, the model computes relationships between tokens directly, which is exactly what you want when one frame needs to stay visually and semantically aligned with frames many steps away.
In practice, transformer architecture video generation means taking the familiar transformer logic and applying it to visual sequences. The model still works with token-like units, still projects them into query, key, and value spaces, and still uses attention to decide what information matters for the next computation. The difference is that the tokens are no longer just words. They can be frame patches, latent patches, compressed spatiotemporal chunks, or other learned visual representations. If you already read language-model diagrams comfortably, you are much closer to understanding video models than it may seem.
The shift from image generation to video generation
The jump from image generation to video generation adds one hard requirement: time. An image model only needs to make one frame look coherent at a single instant. A video model must preserve object identity, camera motion, pose transitions, lighting continuity, and scene structure across many frames. That means it has to capture relationships within each frame and across frames at the same time.
This is why self-attention became so important. Attention is naturally good at long-range dependency modeling, and video needs long-range reasoning everywhere. If a character appears in frame 1 and turns around in frame 36, the system still has to remember clothes, proportions, hair, and environment. If the camera pans from left to right, background geometry must evolve consistently rather than resetting every few frames. Transformer mechanisms are well suited to this because they do not force information to pass only through short local neighborhoods.
Current research direction makes the trend even clearer. High-quality generation has increasingly centered on diffusion models, and one strong line of work explicitly builds diffusion models on transformer backbones. Research discussing state-of-the-art systems notes that diffusion models have overtaken GANs for realistic image and video generation. That matters operationally: when you inspect a serious video generator today, you will often find a denoising process driven by a transformer rather than a plain autoregressive stack generating frames one token at a time.
So, in practice, transformer architecture for video generation is less about copying a text model into a video problem and more about using self-attention as the sequence-modeling engine inside systems designed for spatial detail plus temporal coherence. That framing helps when reading papers, comparing open source ai video generation model options, or deciding whether an image to video open source model is likely to remain stable over longer clips.
Core building blocks of transformer architecture video generation systems
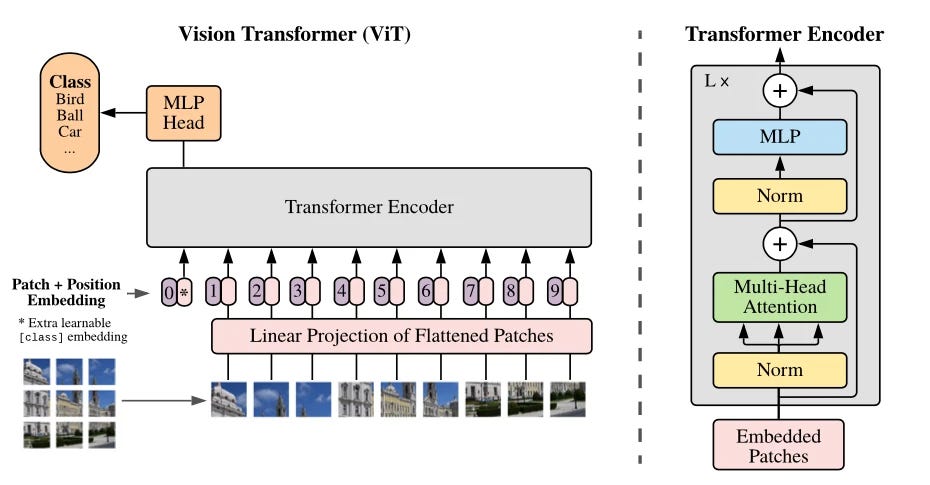
Embeddings, tokens, and video representations
Most modern transformer diagrams look intimidating until you reduce them to a few recurring parts. Start with embeddings. In language, embeddings map tokens into vectors. In video, the same principle holds, but the “token” may be a patch from a frame, a latent patch from a compressed representation, or a spatiotemporal block covering multiple frames. If you see a model turning frames into patches or latents before attention starts, that is the video equivalent of token embedding.
The next practical concept is representation choice. Some systems attend over raw visual patches, but many efficient generators work in latent space because it cuts memory and compute sharply. If a paper describes latent video tokens or compressed visual tokens, that is usually a signal that the architecture is trying to make longer duration or higher resolution feasible. This matters when comparing an open source transformer video model against a heavier design that looks great in demos but cannot scale to production settings.
Attention, residuals, normalization, and MLP layers
After embeddings, the standard transformer pieces appear in a recognizable order. Multi-head self-attention lets the model attend to different relationships in parallel. Query, key, and value projections create the internal spaces where those relationships are computed. Dot-product attention scores how strongly one token should consider another. Scaling keeps those scores numerically stable, masking restricts attention when needed, and softmax converts raw scores into weights. Then come residual connections, layer normalization, and MLP or feed-forward layers to stabilize optimization and expand nonlinear capacity.
Those exact blocks are the visual reading checklist you want when inspecting model diagrams. If you can point to embeddings, multi-head self-attention, Q/K/V projections, softmax, residual paths, normalization, and feed-forward layers, you can usually decode the whole architecture at a useful level. In video systems, these blocks are reused almost unchanged, but they operate on video-relevant tokens instead of text tokens.
A practical way to read model diagrams is to ask three questions. First, where are tokens created: frame patches, latent patches, or 3D spatiotemporal blocks? Second, where is spatial information mixed: attention within a frame, convolutional patch embedding, or spatial transformer blocks? Third, where is temporal information mixed: dedicated temporal attention, joint spatiotemporal attention, or alternating spatial and temporal layers? If the diagram shows separate spatial-attention and temporal-attention paths, the model is making time explicit. If it uses one unified attention over all tokens, it is likely betting on joint sequence modeling at higher memory cost.
This reading habit pays off immediately. If you are evaluating transformer architecture video generation systems, you do not need every implementation detail to tell whether the model is likely designed for short clips, high resolution, or long-range coherence. The architecture diagram usually tells you: token count, latent compression, and whether time gets its own attention pathway are the biggest clues.
How transformer architecture video generation handles spatial and temporal coherence
Modeling frame-to-frame consistency
Temporal coherence is the whole game in video generation. A single beautiful frame is easy compared with twenty seconds of stable motion. Self-attention helps because it lets tokens from one moment directly interact with tokens from distant moments. That direct access is useful when a subject leaves the center of the frame, reappears after occlusion, or changes pose while still needing to remain recognizably the same subject.
For frame-to-frame consistency, the practical question is whether the model can keep appearance and motion linked. In image-only generation, the model solves a one-shot spatial problem: produce consistent texture, layout, and object boundaries inside one frame. In video generation, the model solves a sequence problem on top of that. It must preserve motion continuity, so changes between adjacent frames are neither jittery nor frozen. It also must preserve global continuity, so events over many frames still feel connected. Self-attention is especially strong here because it can relate distant tokens without forcing information to pass through many local steps.
Why long-range dependencies matter in video
The cost of that power is sequence length. Video massively increases token count compared with images. A single high-resolution image already produces many patch or latent tokens. Multiply that by dozens or hundreds of frames, and memory load becomes one of the central architecture constraints. This is why video models often alternate spatial and temporal processing, use latent compression, or adopt sparse or blockwise attention patterns. Those choices are not cosmetic; they decide whether the model can scale while keeping motion stable.
When evaluating a model design, look for direct evidence of temporal handling. If the architecture only describes per-frame image generation and a separate stitching step, expect weak continuity. If it includes explicit temporal attention, joint spatiotemporal token processing, or recurrent latent state updates tied to a transformer backbone, it has a more credible path to stable output. Also check whether the model claims long-duration support and whether that support comes from efficient attention or latent-space processing rather than just brute-force scaling.
Stable subjects usually require the model to preserve identity features across distant frames. Stable motion usually requires temporal pathways that understand trajectories rather than isolated poses. Stable scene structure requires consistent geometry and lighting over time. If a paper or model card highlights efficient long-range attention, temporal layers, or denoising over spatiotemporal latents, those are strong signs the design is trying to solve the right problem.
For practical selection, inspect outputs for three failure modes: subject drift, motion jitter, and background resets. Then tie those failures back to architecture. Models with weak temporal design often look impressive in the first few seconds but collapse in identity or structure as the clip continues. A good transformer video stack should give you a plausible explanation for how it avoids that, not just a polished sample reel.
Transformer-based diffusion models for video generation: the current technical standard

Why diffusion became dominant
The biggest practical shift in generative modeling has been the rise of diffusion. Current technical discussions around image and video generation consistently point to diffusion models as the dominant path for high-quality output, with some sources explicitly noting that diffusion has overtaken GANs for realistic image and video generation. That lines up with what we see in actual systems: diffusion is favored because it produces strong realism, controllable generation, and a training setup that scales more predictably than many GAN pipelines.
For video, diffusion also offers a useful structure for iterative refinement. Instead of forcing the model to generate the final result in one step, the system denoises progressively. That gives the architecture repeated opportunities to enforce appearance, motion, and scene consistency. Once transformers became strong enough as general-purpose sequence backbones, it was natural for researchers to use them inside diffusion systems rather than as isolated autoregressive decoders.
How transformers function inside diffusion pipelines
This is the relationship that matters most today: many leading video systems are transformer-based diffusion models, not plain autoregressive transformers. A transformer backbone is used within the diffusion process to predict or refine denoising steps over visual tokens, often in latent space. Research on a newer class of diffusion models explicitly based on the transformer made that direction clear. The transformer provides the flexible attention mechanism; the diffusion pipeline provides the iterative generation framework.
That combination explains why engineering effort has shifted toward denoising efficiency, memory reduction, and throughput rather than debating transformers versus diffusion as separate camps. Adobe Firefly video work, for example, explicitly discusses optimizations for transformer-based diffusion models to improve performance. This is exactly where production pressure shows up: if the denoiser is transformer-heavy and the sequence is long, even small inefficiencies explode at video scale.
A practical reading rule follows from this. When a model is described as state of the art for video generation, check whether the transformer is serving as the backbone for diffusion denoising. If yes, ask how the denoising tokens are represented, how temporal context is fused, and what efficiency methods are used. If no, and the system is purely autoregressive, ask whether it can actually handle the required sequence length and maintain quality at realistic duration.
This also helps with deployment comparisons. If you are considering an open source ai video generation model or an image to video open source model, the useful distinction is whether it uses a transformer-based diffusion backbone with credible temporal processing. That tells you much more about likely quality and scaling than the label alone. The current standard is not just “transformer video model.” It is an optimized transformer denoiser operating inside a diffusion workflow built for long visual sequences.
Performance, scaling, and optimization tips for transformer architecture video generation
Resolution, duration, and compute trade-offs
Every serious video generation system is negotiating the same three-way trade-off: resolution, duration, and compute. Higher resolution increases spatial token count. Longer duration multiplies sequence length across time. Better temporal consistency usually demands broader attention or more denoising work. You can push any two aggressively, but all three together become expensive very quickly.
A concrete benchmark example from current research is SANA-Video. It is described as a small diffusion model that can efficiently generate video up to 720 × 1280 resolution and minute-length output. That pair of numbers matters. Reaching 720 × 1280 alone is not enough if duration is tiny, and minute-length output alone is not enough if the result only works at low resolution. SANA-Video is useful because it highlights the engineering direction toward efficient long-form generation rather than only headline visual quality.
Memory and throughput optimization strategies
Once you understand the trade-offs, optimization claims become easier to evaluate. If a model advertises better speed, ask whether it achieves that through latent-space generation, blockwise attention, reduced denoising steps, more efficient transformer blocks, or better memory scheduling. If it claims longer clips, check whether it uses explicit temporal compression or a block linear attention structure that scales more gently than naive full attention. These details tell you whether the architecture is fundamentally efficient or merely restricted to easier test cases.
Transformer-based diffusion performance tuning has become a central engineering topic for exactly this reason. Adobe’s work on optimizing transformer-based diffusion models for video reflects the larger industry pattern: teams are trying to keep denoising quality while lowering VRAM pressure and increasing throughput. In production, that often matters more than squeezing out a small gain in benchmark aesthetics.
When comparing systems, use criteria beyond raw sample beauty. Look at maximum supported resolution, maximum stable duration, denoising step count, latency characteristics, and memory behavior. Ask whether the model can run batched prompts efficiently, whether it supports latent caching or chunked generation, and whether temporal consistency degrades sharply with clip length. Those checks are more useful than screenshots.
If you want to run ai video model locally, architecture efficiency becomes even more important. A locally runnable system needs a realistic VRAM footprint, manageable inference time, and documentation that explains quality-speed presets. Also check the open source ai model license commercial use terms before integrating anything into a product workflow. A technically elegant model is not deployable if the license blocks your use case or if its hardware requirements exceed your environment.
How to evaluate and use transformer architecture video generation models

Reading model capabilities before you deploy
The fastest way to avoid bad model choices is to read capabilities through the architecture rather than through marketing clips. Start with architecture type. Is it a transformer-based diffusion model, a plain autoregressive video transformer, or a hybrid image-plus-temporal module? Today, transformer-based diffusion systems usually represent the strongest practical baseline for quality plus controllability.
Next, check temporal handling explicitly. Does the model mention temporal attention, spatiotemporal latent tokens, or separate spatial and temporal transformer layers? If it does not, expect weaker motion continuity. Then check supported resolution and output duration. Claims like 720 × 1280 and minute-length output, as seen with SANA-Video, tell you the system has at least been engineered with scaling in mind. After that, inspect optimization claims. “Efficient,” “optimized,” or “small” only mean something if the paper or repo explains where the savings come from.
For practical selection, compare categories directly. An open source transformer video model may offer deeper architectural transparency and easier customization. An image to video open source model may be better when you need strong conditioning from a single frame or illustration. If you are researching specific repos, terms like happyhorse 1.0 ai video generation model open source transformer often appear in search because developers want a model that is both inspectable and runnable without closed APIs. The key is to map those labels back to architecture, temporal design, and deployment fit.
Sampling controls and practical model selection
Sampling controls matter too, especially in autoregressive settings or hybrid systems that expose token-level generation parameters. Temperature changes randomness: lower temperature usually increases stability and predictability, while higher temperature boosts variation at the risk of drift. Top-k restricts sampling to the highest-probability k options, which can reduce implausible outputs. Top-p, or nucleus sampling, chooses from the smallest set of tokens whose cumulative probability exceeds a threshold, often giving a smoother diversity-quality balance than top-k alone.
In video generation, these controls can affect motion stability as much as visual novelty. If an autoregressive component is too stochastic, you may get frame-to-frame inconsistency or abrupt motion changes. If it is too conservative, motion can become repetitive or unnaturally stiff. The best practice is to treat temperature, top-k, and top-p as coherence controls, not just creativity controls.
For deployment, match model type to task. Use a strong diffusion-based text-to-video model when prompt-driven scene invention matters most. Use an image-to-video model when preserving subject identity from a reference frame is critical. Use a smaller open source ai video generation model when local iteration speed matters more than peak visual fidelity. And if you need to run ai video model locally, verify the full stack: checkpoints, inference scripts, accelerator support, memory recommendations, and license terms.
The most useful evaluation checklist is simple: architecture type, temporal mechanism, supported resolution, supported duration, optimization strategy, sampling controls, local hardware fit, and open source ai model license commercial use status. If a model card cannot answer most of those quickly, it is harder to trust in real work.
Conclusion

The clearest way to understand modern video generation is to stop treating transformers and diffusion as competing ideas and start seeing how they work together. The transformer provides the core sequence-modeling backbone through attention, token mixing, residual pathways, normalization, and feed-forward layers. Diffusion provides the iterative generation framework that currently dominates high-quality image and video synthesis. That combination is why the field has advanced so quickly over the last 2 to 3 years.
When you read a paper, browse an open repo, or compare a production system, focus on the practical architecture questions: what the tokens represent, how temporal information is handled, how the denoiser is built, and what efficiency work makes the model usable at real resolutions and durations. Examples like SANA-Video, with efficient generation up to 720 × 1280 and minute-length output, show that performance is no longer only about bigger models. It is about smarter transformer-based diffusion design.
That is the lens that makes the current landscape easier to navigate. If you can read transformer blocks, identify temporal pathways, and judge optimization claims, you can evaluate transformer architecture video generation systems with much more confidence—whether you are choosing an open source transformer video model, testing an image-to-video pipeline, or preparing a system that needs to run locally at acceptable cost.