AI视频模型Elo评分解读:这些数字意味着什么
如果你曾看过AI视频排行榜,并好奇一个1200分的模型是否真的比1100分的模型更好,答案始于理解Elo衡量了什么——以及它没有衡量什么。
AI视频模型Elo评分究竟意味着什么
Elo最初是国际象棋的评分系统
其基础很简单:Elo是一个衡量相对技能的评分系统,最初由Arpad Elo为国际象棋创建。这个起源很重要,因为它解释了为什么这些数字给人一种竞争而非描述的感觉。Elo从未被设计用来表示一个棋手——或一个模型——具有绝对的质量水平。它旨在根据过去的头对头比赛结果,估计一个竞争者击败另一个竞争者的可能性。
同样的逻辑现在也出现在生成式AI评估中,包括文本到图像和文本到视频的排名。当你看到一个使用Elo的AI视频排行榜时,该平台正在借鉴一种经过实战检验的竞争性游戏方法,并将其应用于成对判断。你面对的不是两个棋手,而是两个视频模型。你面对的不是将死,而是根据基准标准判断出的赢家。
对于任何搜索ai video model elo rating explained的人来说,首先要明确的是:Elo是一个相对技能评分系统,而不是一个永远贴在模型上的客观“视频质量分数”。1200分只有与同一池中其他模型的评分进行比较时才有意义。
为什么AI视频基准测试使用头对头较量
成对比较在AI视频中很受欢迎,因为它们通常比给单个输出打出完美分数更容易判断。如果两个模型从同一个提示生成视频片段,人类评委通常可以判断哪个更好地遵循了提示,看起来更清晰,感觉更具电影感,或者仅仅是整体上更受偏爱。Elo将这些许多小的胜负决定转化为一个排名。
这种结构是Elo如此适用于生成系统的重要原因。当评估者在相同的测试条件下,更喜欢一个模型的输出而不是另一个模型的输出时,该模型就“赢得”了一场较量。输家会掉分;赢家会得分。随着时间的推移,许多成对结果会产生一个排行榜,反映出谁最常获胜。
有用的启示是实用的:Elo回答的问题是,“在这个基准测试中,哪个模型倾向于击败其他模型?”它没有回答,“哪个模型普遍最适合所有项目?”这些是不同的问题,将它们混淆是大多数排行榜混乱的根源。
所以,当你查看AI视频排名时,将数字视为竞争领域中的一个位置。如果排行榜发生变化,评分也会随之变化,因为Elo始终是相对于被比较的模型和收集到的结果而言的。这是任何可靠的ai video model elo rating explained讨论的核心:这个数字只有在产生它的基准测试内部才有意义。
AI视频模型Elo评分在实践中是如何计算的
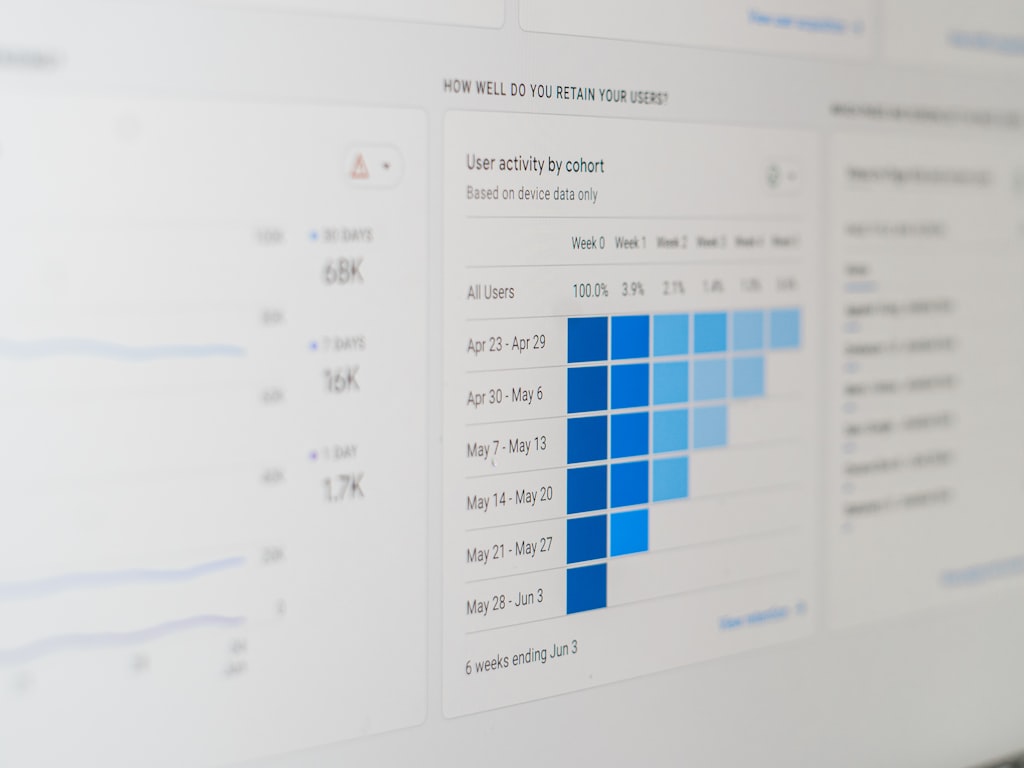
预期结果与实际结果
Elo评分在每次较量后都会更新,更新取决于两件事:预期会发生什么和实际发生了什么。如果一个高评分模型面对一个低评分模型,高评分模型预计会更常获胜。如果这个热门模型获胜,它只会获得少量分数,因为结果并不令人意外。如果弱者获胜,评分变化会更大,因为结果出乎意料。
这种预期与实际的结构是整个引擎。它使Elo比简单的胜场计数器更有用。模型不仅仅因为获胜而获得奖励;当它击败更强的对手时,它会获得更多奖励。同样,输给较弱的模型比输给较强的模型损失更大。
在AI视频基准测试中,这意味着每一次判断的比较都提供了信息。一个提示可能比较模型A和模型B的真实感。另一个可能比较模型C和模型A的运动一致性。还有一个可能要求评委给出整体偏好。每个结果都会以小幅增量更新评分。
为什么评分在每次较量后都会变化
在实践中,AI视频基准测试会进行大量的头对头较量。两个模型为同一个提示生成输出,评估者选择赢家。获胜模型得分,失败模型失分,评分系统重新计算它们的排名。重复这个过程数百或数千次,你就会得到一个由许多小判断而非一次大型评审构建的排行榜。
这就是为什么Elo排行榜感觉充满活力。评分不是固定的徽章。它们会随着新的比较数据、新模型的加入或评估条件的变化而移动。如果一个模型开始持续击败强劲的竞争对手,它的评分就会攀升。如果它反复失败,特别是输给评分较低的系统,它就会下降。
对于试图解释分数差距的读者来说,重要的部分是概率。较大的Elo差距通常表明,在一个基准测试中,一个模型预计会比另一个模型更常获胜。较小的差距则表明竞争更激烈,两个模型都可能获胜,具体取决于提示或评判标准。你不需要记住公式就能利用这个洞察。只需记住,Elo是通过重复结果来估计相对强度的。
这也是为什么只有少数较量的排行榜可能会有“噪声”。基于稀疏比较的评分可能看起来很精确,但它不如基于广泛、重复判断的评分值得信赖。如果你正在使用Elo来选择生产工具,请检查排名是否来自大量的比较,而不仅仅是少数几个样本较量。
一个实用的阅读策略是:如果模型X在许多成对测试后显著高于模型Y,这通常意味着模型X在该基准测试中积累了更强的判断胜场记录。这并不自动意味着它将更适合你的确切工作流程,但这确实意味着该评分是基于实际比较结果,而非炒作。
如何阅读AI视频模型Elo排行榜而不误解数字

更高的评分通常告诉你什么
更高的评分通常非常清楚地告诉你一件事:在该评估环境中,它获胜的次数更多。这可能意味着评委整体上更喜欢它的视频片段,认为它对提示的遵循更强,更喜欢它的视觉质量,或者判断它的运动更流畅——这取决于基准测试的设计方式。
因此,如果一个模型在同一个排行榜上是1240分,另一个是1160分,那么评分更高的系统通常在该基准测试的头对头较量中表现更好。这是有用的信息,因为它能穿透模糊的市场营销语言。Elo为你提供的是比较胜场的记录,而不是公司自吹自擂的描述。
对于快速决策,将Elo视为一个方向性信号。分数越高通常意味着基准测试性能越强。小的差距可能意味着“大致处于同一级别”,而较大的差距通常表明在该特定排名中具有更可靠的优势。如果你正在比较两个分数相近的模型,不要夸大其差异。如果一个模型遥遥领先,并且通过大量比较达到了这个位置,那么这个差距值得关注。
这个数字不能保证什么
Elo不能保证什么同样重要。它不能保证普遍的视频生成质量。它不能保证更适合你的提示、你的受众、你的编辑流程或你的客户修改。它本身绝对不会告诉你任何关于速度、定价、控制工具、API稳定性或许可的信息。
这正是人们经常滥用排行榜的地方。Elo反映的是特定基准测试中的相对地位,而不是关于所有视频创作的普遍真理。一个模型可能因为擅长短视频、精致的通用提示或整体人类偏好测试而排名靠前,但同一个模型可能在小众动画风格、品牌产品拍摄或长篇场景连贯性方面表现不佳。
阅读任何排行榜的清晰方法是在信任数字之前问四个问题:
- 评委实际选择的是什么:提示遵循度、视觉质量、运动真实感还是整体偏好?
- 提示是否与你需要制作的作品相似?
- 有多少次比较产生了该排名?
- 所有模型是否在一致的条件下进行了测试?
如果这些答案与你的用例相符,那么该评分就会变得更有用。如果它们不相符,排行榜仍然有趣,但不足以做出购买或工作流程决策。
这是正确ai video model elo rating explained的实用核心:高分意味着在特定背景下更强,而不是在所有背景下都更好。将相近的分数视为激烈竞争,将较大的差距视为更强的分离证据,并且在将数字视为金科玉律之前,务必检查评判标准。
AI视频模型Elo评分解读与实际应用中的注意事项
为什么基准测试的胜利不总是等同于更好的生产结果
Elo在排名相对性能方面表现出色,但AI系统并非国际象棋棋手。研究人员指出,从国际象棋和体育运动中改编的排行榜方法并不总是能完美地映射到AI上。这个警告对于视频生成来说非常重要,因为结果会根据提示风格、视频片段长度、运动要求和后期制作需求而大相径庭。
一个模型可能在基准测试中占据主导地位,但对于生产工作流程来说仍然是错误的工具。也许它能创建华丽的短视频,但在生成较长视频时却崩溃了。也许评委喜欢它的电影感外观,但它在严格遵循提示方面表现不佳。也许它赢得了广泛的偏好测试,但你的实际工作需要产品演示的技术一致性或广告创意中非常具体的视觉风格。
这就是为什么高基准测试性能不自动意味着对每个用户或应用程序来说都是“更好的AI”。如果你的工作流程依赖于快速迭代、种子控制、摄像机运动选项、一致的角色身份或轻松的放大,那么这些因素可能比排行榜上的优势更重要。
评估设计如何影响排名
评估的设计对排名的影响超出了许多人的认知。如果基准测试强调整体人类偏好,它可能会奖励戏剧性、精致的视频片段。如果它强调提示遵循度,一个更字面化的模型可能会脱颖而出。如果它只比较短视频生成,长序列的可靠性可能就看不见了。Elo数字反映了所有这些选择,因为它是由基准测试要求评委产生的结果构建的。
这意味着上下文限制不是次要问题;它们是分数的一部分。在依赖任何基于Elo的AI视频排名之前,请运行此清单:
- 检查评判目标:整体偏好、提示遵循度、视觉质量、运动一致性或综合评分。
- 检查提示集:通用提示、电影感提示、小众提示、品牌重点提示或技术指令提示。
- 检查视频片段长度:短基准视频片段可能会隐藏长视频生成中的失败模式。
- 检查模型设置:长宽比、推理步数、引导、种子控制以及任何后期处理都可能影响结果。
- 检查评委类型:人类评分员、专家评分员、众包评分员或混合设置。
- 检查时效性:快速发布的新模型可能使旧的Elo快照过时。
- 检查样本数量:更多的成对较量通常意味着更高的置信度。
这对于为实际工作比较工具的创作者来说很重要。一个排名靠前的基准测试赢家可能仍然在社交广告、动漫风格视觉效果、低预算实验或高度受限的产品拍摄方面表现不佳。Elo是比较强度的捷径,而不是替代实际验证的方法。
所以,如果你想要最实用的ai video model elo rating explained,请将Elo视为一张地图,显示在特定规则下谁倾向于获胜。然后测试这些规则是否与你实际需要交付的视频类型相符。
如何在选择模型时使用AI视频模型Elo评分

将Elo作为一种信号,而不是唯一的信号
使用Elo的最佳方式是将其作为过滤器,而不是最终裁决。它非常适合缩小拥挤的候选范围。如果一个模型始终位居可信排行榜的榜首,它就值得关注。但在你做出承诺之前,请将该评分与真正影响生产的因素放在一起考虑:样本输出、每次生成的成本、渲染速度、编辑控制、摄像机选项、可靠性和许可条款。
如果你正在为客户工作选择工具,这一点尤为重要。如果一个Elo评分略低的模型能为你提供更强的提示控制、更好的一致性、更快的周转时间或更可预测的商业交付权利,那么它可能是更好的选择。基准测试的赢家不总是工作流程的赢家。
在信任排名之前要问的问题
当您对其进行压力测试时,排名才变得具有可操作性。从这些问题开始:
- 所有模型是否在相同的提示集和生成设置下进行了比较?
- 判断是否在许多成对比较中保持一致?
- 基准测试是否反映了你最关心的问题:电影质量、提示遵循度、风格化、真实感还是实验性?
- 是否有足够的较量来信任排名顺序?
- 模型是当前版本,还是你正在比较过时的版本?
如果排行榜无法回答这些问题,请谨慎使用它。
一个实用的候选名单框架在这里很有效:
- 扫描顶层。 选择三到五个Elo排名靠前的模型,而不是执着于精确的#1。
- 匹配你的主要工作。 对于广告,优先考虑提示遵循度和精致的输出。对于探索,优先考虑灵活性和成本。对于叙事作品,优先考虑运动连贯性和一致性。
- 查看样本画廊。 不要只依赖数字而不看实际的视频片段。
- 检查业务限制。 比较定价、排队时间、API访问、导出质量和商业权利。
- 进行一次小型比拼。 在你的候选名单上使用相同的五到十个提示,并并排比较结果。
- 评估你的工作流程匹配度。 根据质量、可控性、速度、成本和可靠性对每个模型进行评分。
- 选择最佳的整体匹配。 赢家是那些在Elo和你的实际生产设置中都表现良好的模型。
这个过程可以避免你为不符合你用例的基准测试冠军支付过高的费用。Elo告诉你谁倾向于在头对头较量中获胜。你自己的测试告诉你谁能帮助你更快更好地完成项目。
对于初学者来说,这种方法消除了很多噪音。对于经验丰富的创作者来说,它能防止代价高昂的错误。使用Elo来寻找竞争者,然后让你自己的提示集和交付要求决定最终排名。
AI视频模型Elo评分解读:开源和本地视频模型比较

比较商业和开源AI视频生成模型选项
当你比较专有平台和open source ai video generation model时,Elo也很有用。其价值是相同的:它为你提供了哪些系统在成对评估中倾向于获胜的相对读数。如果一个商业模型以很大的优势超越一个开源模型,这告诉你专有系统可能拥有更强的基准测试记录。如果分数接近,那么开源模型可能值得积极测试,因为成本和灵活性的权衡可能对其有利。
当你评估image to video open source model、更广泛的open source transformer video model,或者人们通过名称追踪的小众版本,例如搜索happyhorse 1.0 ai video generation model open source transformer时,这一点变得尤为重要。在所有这些情况下,Elo都可以帮助你从“我在社交媒体上看到了这个模型”转变为“在相同的评判设置下,它实际击败替代品的频率是多少?”
这种相对视角非常强大,因为开源和封闭系统通常不仅在输出质量上有所不同。专有工具可能在精致度和便利性上取胜。开源模型可能在定制、隐私或部署控制上取胜。Elo有助于比较竞争强度,但它不会抹去这些实际差异。
如果你想在本地运行AI视频模型,需要检查什么
如果你的目标是run ai video model locally,排名只是决策的一部分。你还需要检查硬件要求、VRAM需求、推理速度、安装复杂性、模型权重可用性以及许可证是否允许你的预期用途。这是许多排行榜读者犯下昂贵错误的地方:他们将一个强大的开源模型列入候选名单,却没有验证他们是否真的能够运行它或用它来交付商业作品。
使用这个快速本地测试清单:
- 验证排名中使用的确切模型变体。
- 检查最低和推荐的GPU/VRAM要求。
- 确认推理脚本和依赖项是否得到维护。
- 审查本地硬件上的输出长度和分辨率限制。
- 检查模型是否支持image-to-video、text-to-video或两者都支持。
- 仔细阅读open source ai model license commercial use条款。
- 确认是否允许微调、再分发或客户交付。
如果一个Elo排名靠前的开源模型也符合你的机器和法律需求,它可能是一个很好的选择。例如,你可以使用Elo将一组基于Transformer的视频系统缩小到两三个选项,然后用你自己的提示在本地测试这些选项。这比仅仅根据GitHub星标或炒作视频进行选择要明智得多。
这正是ai video model elo rating explained视角真正有帮助的地方:排名为你提供了一个比较性能的起点,而你的本地测试则揭示了速度、控制、稳定性和可部署性的真实情况。特别是对于开源模型,这种组合比单独的排名更重要。
结论

Elo最好被理解为一种实用的捷径,用于比较哪些AI视频模型倾向于在头对头较量中获胜。因为它源自Arpad Elo最初为国际象棋构建的相对评分系统,所以当你将其解读为特定排行榜中的相对强度时,这个数字最有用——而不是作为视频质量的普遍衡量标准。
更高的评分通常意味着一个模型在该基准测试的评判较量中获胜次数更多。较大的差距通常表明预期胜率更高。但这个数字只反映了测试的规则:使用的提示、评判标准、比较数量以及排行榜背后的设置。
这就是为什么使用Elo最明智的方式很简单。从它开始。充分信任它以缩小范围。然后根据你自己的生产目标对其进行验证,无论是电影般的视觉效果、严格的提示遵循、本地部署、商业许可还是预算友好的实验。当你将排行榜背景与真实样本测试相结合时,Elo就变成了它最好的样子:一个快速、有用的信号,帮助你更自信地做出选择,而无需假装它能独自回答所有问题。