Who Built HappyHorse? What We Actually Know About the Mystery Team Behind the #1 AI Video Model
HappyHorse-1.0 is getting talked about like a breakout AI video model, but the useful question is not the hype cycle. The useful question is what can actually be verified about the people or organization behind it. Right now, that distinction matters a lot more than another recycled “dark horse” headline, because the supplied material points to a model that is newsworthy precisely because its authorship is still unclear.
Who built HappyHorse team: the short answer based on verifiable sources
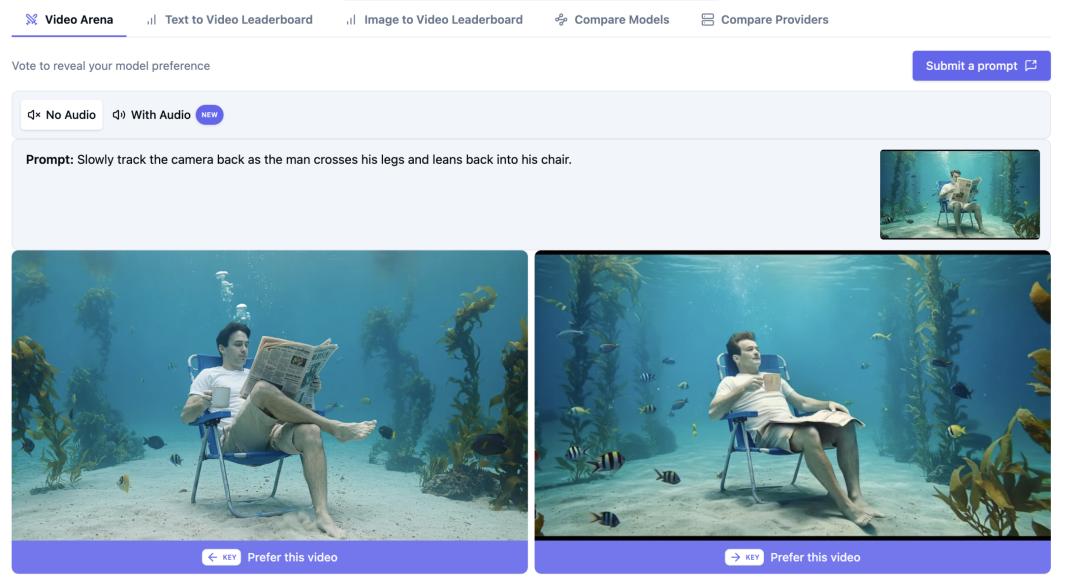
What is confirmed right now
The clearest source-backed answer is simple: based on the supplied material, no publicly confirmed builder has been identified for HappyHorse-1.0. That is the strongest takeaway because it comes from explicit language in the research rather than guesswork. A Dzine AI piece titled “HappyHorse 1.0 - #1 Ranked AI Video Generator” states plainly: “Who made HappyHorse 1.0? The team is unknown.” A separate source, “Is HappyHorse-1.0 Open Source? What We Can Verify,” adds an even tighter verification note: “nobody has publicly confirmed who built HappyHorse-1.0.”
That matters because it gives us a clean baseline. If someone claims the team is definitely known, they are already going beyond what the supplied sources actually verify. The other important confirmed detail is the reported leaderboard framing. The same verification-focused source says Artificial Analysis described the submission as pseudonymous. In practical terms, that means the leaderboard entry is not clearly tied, in the provided material, to a fully identified company or named team. If you are trying to determine operator identity, who signs the terms of service, or who would be accountable for data handling, that pseudonymous label is not a minor footnote. It is the central fact.
There is also a confirmed media pattern around the model’s positioning. Secondary coverage is describing HappyHorse-1.0 as a top or top-ranked AI video model. One example in the notes is the DEV Community article title: “Who Developed HappyHorse-1.0? The Behind-the-Scenes Story of the Open-Source Dark Horse Storming the AI Video Generation Throne.” But that is still headline-level coverage. The supplied excerpt does not include the underlying benchmark data, benchmark methodology, or direct ranking table details.
What is still unconfirmed
What remains unconfirmed is the exact builder, company structure, internal lab, and legal operator behind HappyHorse-1.0. The current evidence does not publicly verify a named founding team, official corporate entity, or signed statement from a company claiming ownership. It also does not verify technical architecture, training data, pricing, support, licensing, or whether the model is truly an open source ai video generation model despite some coverage implying that angle.
That is why the best way to read the who built HappyHorse team question is in three layers: verified facts, plausible leads, and unsupported speculation. Verified facts: the team is publicly unknown in the supplied sources, and the submission was reportedly described as pseudonymous. Plausible leads: Alibaba, Taotian Group, and a Future Life Laboratory attribution appear in snippets and reports. Unsupported speculation: anything that jumps from those leads to “confirmed by X company” without primary evidence.
If you need one sentence to anchor your thinking, use this: no publicly confirmed builder is identified in the supplied material, and every more specific attribution should be treated as a lead awaiting proof.
What the public evidence says about the who built HappyHorse team mystery

Source-by-source evidence review
The public trail in the supplied research is thin but readable if you separate source types. First, there is secondary coverage. The DEV Community title calling HappyHorse-1.0 an “open-source dark horse” storming the AI video generation throne is attention-grabbing, but it is still a secondary framing device. The supplied excerpt does not show benchmark numbers, source documents, or a direct statement from a builder. So if you see claims that HappyHorse-1.0 is definitively #1, treat that as coverage unless the actual benchmark table is shown and attributable.
Second, there are verification-oriented snippets. The strongest two are from Dzine AI and the verification article mentioned in the notes. Those sources explicitly say the team is unknown and that nobody has publicly confirmed who built HappyHorse-1.0. Those statements do not solve the mystery, but they are useful because they narrow the range of safe claims.
Third, there are leaderboard references. The note that Artificial Analysis described the submission as pseudonymous is a key piece of evidence. It tells you the model may have entered a benchmark ecosystem without a fully transparent organizational identity attached in the publicly visible materials provided here. If you are trying to validate vendor accountability, pseudonymous submissions require extra caution.
Fourth, there is influencer commentary. The notes mention multiple influencers posting that the team is Zhang Di’s Taotian Group Future Life Laboratory. That can be useful for pattern spotting because repeated claims often reveal where the rumor cluster is forming. But repetition on social platforms does not turn a claim into proof.
How to read pseudonymous model submissions
A pseudonymous submission matters because it changes the burden of verification. For buyers, it affects procurement and risk review: you cannot assume the listed name maps cleanly to a legal entity that can sign enterprise terms. For creators, it affects commercial confidence: if a client asks who operates the model, “people online think it’s Alibaba-adjacent” is not an answer you can rely on. For researchers, it affects reproducibility and accountability: the model may be benchmarked publicly while the team identity remains obscured.
A practical way to evaluate any attribution claim is to sort it into one of three buckets. Primary evidence includes an official announcement, company blog, model card, repository owned by a named organization, legal terms naming the operator, or a direct statement from an identifiable spokesperson. Secondary reporting includes articles summarizing claims, titles calling a model #1, and commentary that references unnamed sources. Rumor includes screenshots without provenance, incomplete snippets, reposted claims, and social posts that cite each other.
That checklist is the fastest way to handle the who built HappyHorse team mystery without getting pulled into circular sourcing. If a claim about HappyHorse starts with “people are saying,” move it to rumor until you can trace it back to primary evidence.
Alibaba, Taotian Group, and Zhang Di: the strongest leads on who built HappyHorse team

The Alibaba and Taotian Group claim
The strongest attribution lead in the supplied material is the Alibaba angle. One report titled “Could HappyHorse be Z-video in disguise, from Alibaba?” says HappyHorse-1.0 comes from Alibaba’s Taotian Group. That is a meaningful clue because it points to a specific major company division rather than a vague startup rumor. If true, it would radically change how people should assess the model’s backing, engineering depth, and operational maturity.
But the key phrase is if true. The supplied material does not include primary proof for that claim. There is no official Alibaba announcement in the research notes, no company-owned repository, no model card signed by Alibaba, and no direct corporate statement confirming authorship. So the right way to use this report is as a lead worth tracking, not as a settled fact.
This is where repeated claims can mislead even experienced builders and operators. Once one source ties a model to a recognizable company, social commentary tends to compress “reported connection” into “confirmed owner.” That jump is exactly what the current evidence does not support. If you are evaluating the claim seriously, compare every mention against a primary artifact: official domain, named legal operator, or public documentation that can be traced back to the organization itself.
The Future Life Laboratory attribution
The second major lead is more specific but also more fragile. A snippet from “Who Developed HappyHorse-1.0?” says: “The team behind HappyHorse-1.0 is Zhang Di’s Taotian Group Future Life Laboratory (built by ATH-AI Innovation…” The problem is that the snippet is incomplete. Because the sentence cuts off, it cannot be treated as a complete, self-sufficient confirmation. It is a directional clue, not a finalized attribution.
Still, it is valuable because it overlaps with the broader Taotian Group claim. That overlap is exactly how to compare imperfect sources. Across the supplied materials, the consistent thread is not “confirmed Alibaba ownership.” The consistent thread is narrower: multiple references point toward Alibaba’s Taotian Group or a Taotian-linked internal lab. That consistency makes the lead stronger than a random rumor, but it still does not clear the bar for verification.
The influencer posts mentioned in the notes fit the same pattern. Multiple influencers reportedly posted that the team is Zhang Di’s Taotian Group Future Life Laboratory. Use that as a signal for pattern matching only. Repetition can show that a claim is circulating widely, but it cannot establish authorship by itself. To upgrade the claim from “plausible lead” to “confirmed fact,” you would need a direct statement from Alibaba, Taotian Group, the laboratory itself, or a documented repository or model release controlled by that organization.
So when comparing overlapping claims, look for what remains stable across sources: Taotian appears repeatedly; Alibaba appears repeatedly; Future Life Laboratory appears in at least one snippet and in influencer repetition. What still needs verification is whether those references are official, current, and tied to the exact model called HappyHorse-1.0 rather than a rumored relation or alias.
How to verify who built HappyHorse team before you use the model for work
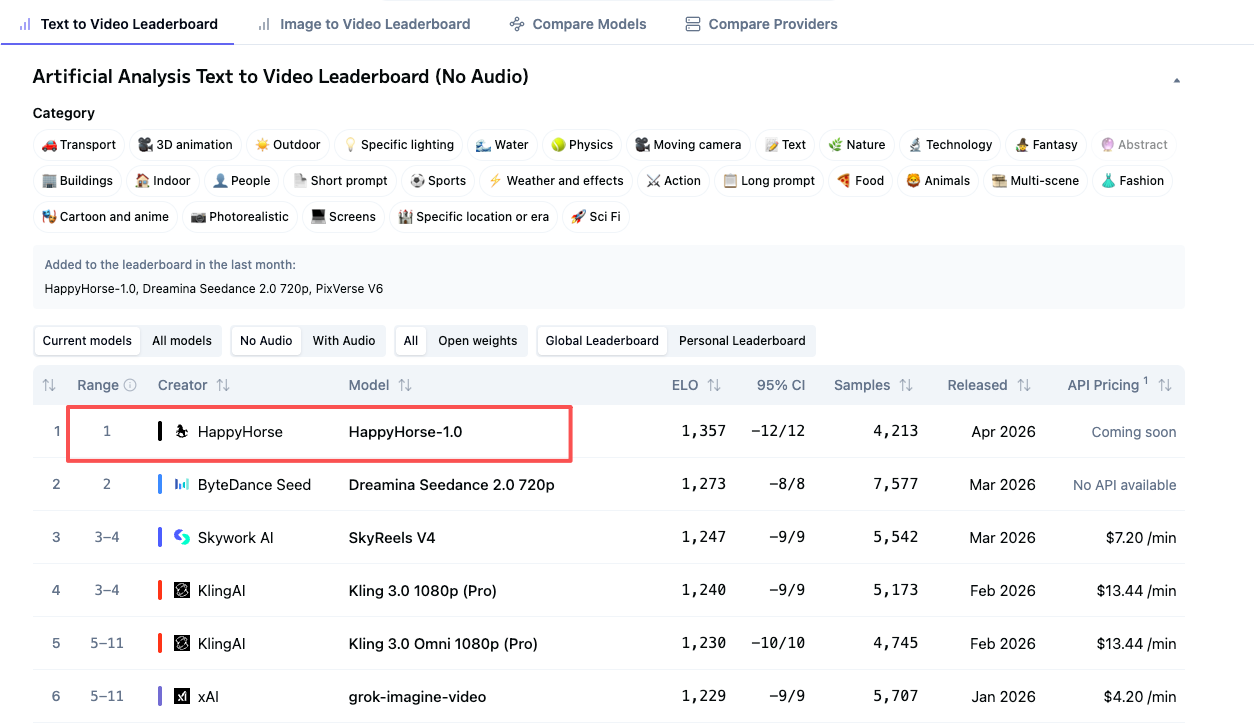
A practical due diligence checklist
If you are considering HappyHorse-1.0 for real work, use a hard verification workflow before touching production. Step one: identify the operator. Find the legal entity name behind the service, API, repo, or download page. If the model is presented as an open source ai video generation model, verify whether the publisher is a named organization or an anonymous account. Step two: find official documentation. Look for a model card, technical report, company page, or official announcement that explicitly claims authorship.
Step three: confirm the terms of service and license. This is where many teams get tripped up with video tools. If the release suggests an image to video open source model or an open source transformer video model, inspect the actual license file and usage terms. “Open” branding is not enough. You need the exact terms governing commercial use, modification, redistribution, and hosted service operation. For client work, the query to answer is basically: what does the open source ai model license commercial use language actually permit?
Step four: verify privacy and data handling. If prompts, uploads, reference images, or generated videos pass through a hosted service, check whether the operator states retention periods, training reuse policies, and deletion controls. Step five: confirm hosting and support details. Is this a self-hosted release, a gated API, or a benchmark-only entry with no public deployment documentation?
The due diligence gap in the current research is obvious: no verified company identity, no confirmed public team, and no sourced enterprise details such as SLA, uptime, support tier, or security commitments. That does not mean the model is bad. It means you do not yet have enough verified operator information to treat it like a normal enterprise vendor.
Questions to answer before production use
Before production use, get explicit answers to five questions. Who operates the model legally? What are the commercial rights? Where is the model hosted? What happens to uploaded assets? What support path exists if results fail or service breaks? If those answers are missing, keep the model in evaluation mode.
The same checklist applies if you are evaluating any run ai video model locally workflow. If local execution is possible, confirm whether weights are actually available, whether inference is permitted under the license, and whether any usage restrictions survive local deployment. Plenty of projects sound open until you inspect the release terms.
For legal and procurement review, keep a short list: license terms, commercial-use permissions, support channels, model hosting details, named operator, privacy policy, data retention statement, and any indemnity or limitation language that affects client delivery. If even half of those items are absent, you are not looking at a production-ready procurement package yet.
What creators and founders should do if the who built HappyHorse team question remains unanswered

Using the model safely for experiments
If the authorship question stays unresolved, the smart move is to separate output quality from vendor trust. You can still test motion quality, prompt adherence, temporal consistency, and artifact rates in a sandbox without assuming the model is commercially ready. That gives you useful signal while keeping risk bounded. For experiments, use non-sensitive prompts, avoid client assets, and document exactly where the model was accessed from and what terms were visible at the time.
That distinction is crucial because the supplied research only verifies uncertainty around attribution. It does not verify technical architecture, pricing, support, licensing, or whether HappyHorse-1.0 is publicly accessible in a stable product form. So if test results look great, treat that as evidence about generated output only, not about legal usability or operator reliability.
A practical staged path works best. Start with sandbox testing on disposable or synthetic inputs. Record whether the interface, repo, or benchmark page names an operator. Save screenshots of terms, license text, and any public statements. If the model later becomes relevant for commercial work, move to a formal review only after you have a traceable source of ownership and rights.
When to avoid production dependency
Avoid production dependency when ownership, data policy, and service reliability remain unverified. For marketing workflows, that means no client delivery promises based solely on ranking claims. A model can be buzzworthy and still be impossible to clear through procurement. If you cannot identify who runs the service, where assets are stored, and what commercial permissions apply, do not make it a dependency inside a campaign pipeline.
The same goes for startups evaluating growth tooling. Require verified ownership, privacy language, support contacts, and service continuity details before integrating the model into automated content flows. The current notes do not verify uptime, SLA, enterprise support, pricing, or licensing. That is enough to block operational trust even if the model’s output is excellent.
What can be inferred from the supplied research is narrow but useful: authorship uncertainty is real, pseudonymous framing has been reported, and Alibaba/Taotian-related attributions remain leads rather than confirmed facts. What cannot be inferred is everything teams usually need for go-live decisions: architecture, deployment model, support obligations, pricing, and commercial rights.
That is why the safest adoption path is staged: sandbox testing first, legal review second, limited deployment only after source and rights verification, and broader rollout only when the operator identity is documented in primary sources.
HappyHorse-1.0 in context: what to watch next on open source AI video generation model claims

Signals that would confirm the team
The evidence needed to confirm the builder is straightforward. An official announcement from a named organization would do it. So would company documentation, a repository owned by a verified organization account, a model card naming the team, or a direct statement from Alibaba, Taotian Group, or another specific company claiming HappyHorse-1.0. Those are the artifacts that would move the story from “mystery with strong leads” to “confirmed origin.”
A benchmark disclosure would also help. If a leaderboard entry links back to an official release page, technical report, or documented submitter identity, that would close much of the current attribution gap. Right now, the reported pseudonymous submission framing means the benchmark visibility does not automatically solve authorship.
How this affects open source and local-use interest
This mystery matters because it intersects with the exact searches people are already making: open source ai video generation model, open source transformer video model, image to video open source model, and run ai video model locally. HappyHorse-1.0 is attracting attention in that orbit, but the current research does not confirm whether it is truly open source, whether weights are available, or what commercial-use license applies. Even the phrase happyhorse 1.0 ai video generation model open source transformer should be treated as a search pattern, not a confirmed technical description.
That means anyone tracking local-use or self-hosting possibilities should wait for concrete artifacts: official repos, downloadable weights, inference instructions, hardware requirements, and a license file that clearly grants the intended rights. Without those pieces, a model may be benchmark-famous while still being unusable for actual local workflows or client work.
A solid monitoring checklist keeps this simple. Watch for: official repositories under a named organization, license files, model cards, benchmark disclosures with methodology, organization pages that list the project, legal terms naming the operator, and independent verification from credible analysts who link back to primary evidence. If a future announcement ties HappyHorse-1.0 directly to Alibaba’s Taotian Group or to Zhang Di’s Future Life Laboratory through official documentation, that would materially change the risk picture.
For now, the most accurate answer remains the least flashy one. HappyHorse-1.0 is being talked about as a top AI video model, but its team is still publicly unconfirmed in the supplied material. The Alibaba, Taotian Group, and Future Life Laboratory attributions are the strongest leads on who built HappyHorse team, yet they remain leads until primary evidence appears. If you are evaluating the model seriously, treat benchmark buzz as separate from operator trust, and verify ownership, rights, hosting, and data handling before any production use.