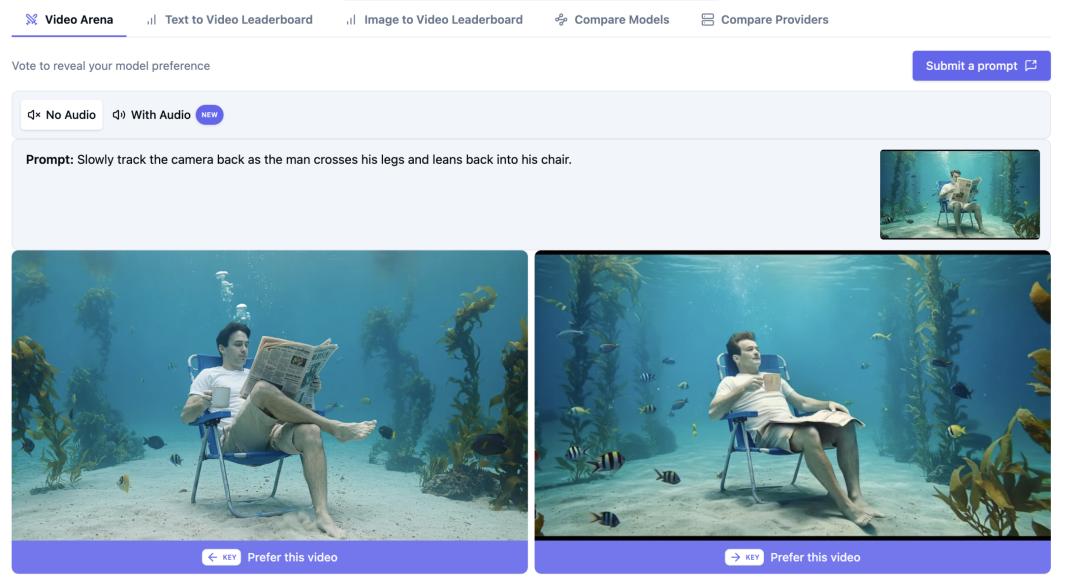
谁打造了 HappyHorse?关于这个排名第一的AI视频模型背后神秘团队的真实信息
HappyHorse-1.0 正被热议为一款突破性的AI视频模型,但有用的问题并非炒作周期。有用的问题是,关于其背后的人员或组织,哪些信息是真正可以验证的。目前,这种区分比又一个“黑马”头条新闻重要得多,因为现有材料表明,这个模型之所以具有新闻价值,恰恰是因为其作者身份仍不明确。
谁打造了 HappyHorse 团队:基于可验证来源的简短回答
目前已确认的信息
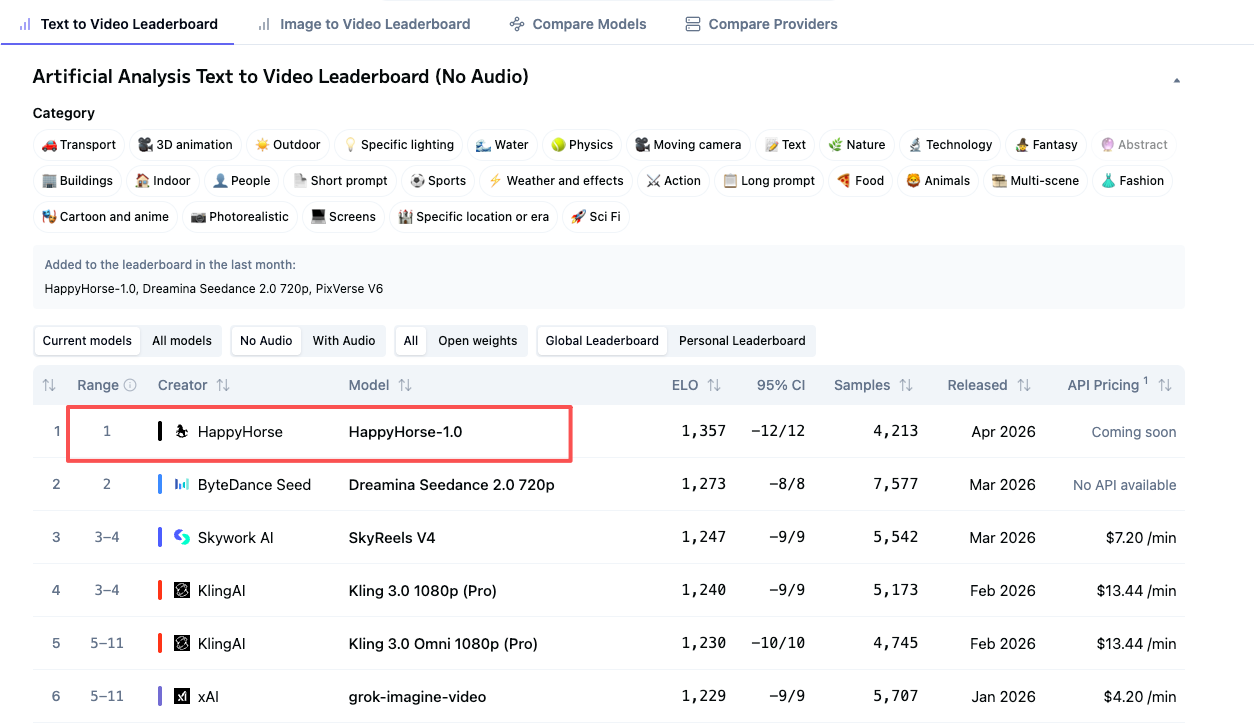
最清晰且有来源支持的答案很简单:根据现有材料,HappyHorse-1.0 尚未确认任何公开的开发者。这是最有力的结论,因为它来自研究中明确的措辞,而非猜测。一篇名为《HappyHorse 1.0 - #1 Ranked AI Video Generator》的 Dzine AI 文章明确指出:“HappyHorse 1.0 是谁制作的?团队未知。”另一份来源,《Is HappyHorse-1.0 Open Source? What We Can Verify》则补充了一个更严格的验证说明:“没有人公开确认 HappyHorse-1.0 是谁开发的。”
这一点很重要,因为它为我们提供了一个清晰的基线。如果有人声称团队明确已知,他们就已经超出了现有来源实际验证的范围。另一个重要的确认细节是所报道的排行榜定位。同一份注重验证的来源称,Artificial Analysis 将该提交描述为匿名的。实际上,这意味着在所提供的材料中,排行榜条目并未明确与一家完全确定的公司或具名团队关联。如果你试图确定运营方身份、谁签署服务条款,或者谁将对数据处理负责,这个匿名标签并非无关紧要的脚注。它是核心事实。
围绕该模型定位,还存在一个已确认的媒体模式。次级报道将 HappyHorse-1.0 描述为顶级或排名靠前的AI视频模型。笔记中的一个例子是 DEV Community 文章标题:《Who Developed HappyHorse-1.0? The Behind-the-Scenes Story of the Open-Source Dark Horse Storming the AI Video Generation Throne.》但这仍然是标题层面的报道。提供的摘录不包括底层的基准数据、基准方法或直接的排名表细节。
仍未确认的信息
仍未确认的是 HappyHorse-1.0 背后的确切开发者、公司结构、内部实验室和法律运营方。目前的证据并未公开验证具名的创始团队、官方公司实体,或来自声称拥有所有权的公司签署的声明。它也未验证技术架构、训练数据、定价、支持、许可,以及该模型是否真的是一个 open source ai video generation model,尽管有些报道暗示了这一角度。
这就是为什么阅读谁打造了 HappyHorse 团队这个问题时,最好分三层:已验证的事实、合理线索和缺乏证据的猜测。已验证的事实:在现有来源中,该团队是公开未知的,并且据报道该提交被描述为匿名的。合理线索:在片段和报告中出现了阿里巴巴、淘天集团和未来生活实验室的归属。缺乏证据的猜测:任何从这些线索跳到“X公司已确认”而没有原始证据的说法。
如果你需要一句话来锚定你的思考,请使用这句话:现有材料中没有识别出任何公开确认的开发者,每一个更具体的归属都应被视为有待证实的线索。
公开证据表明了 HappyHorse 团队之谜的哪些信息

逐源证据审查
现有研究中的公开线索很少,但如果将来源类型分开,仍然可读。首先是次级报道。DEV Community 将 HappyHorse-1.0 称为“开源黑马”并“席卷AI视频生成宝座”的标题引人注目,但这仍然是一种次级框架。提供的摘录没有显示基准数字、原始文件或来自开发者的直接声明。因此,如果你看到声称 HappyHorse-1.0 绝对是第一名的说法,请将其视为报道,除非实际的基准表被展示且可归因。
其次,有面向验证的片段。最强的两个来自 Dzine AI 和笔记中提到的验证文章。这些来源明确表示团队未知,并且没有人公开确认 HappyHorse-1.0 是谁开发的。这些声明并没有解开谜团,但它们很有用,因为它们缩小了安全声明的范围。
第三,有排行榜参考。Artificial Analysis 将该提交描述为匿名的说明是一个关键证据。它告诉你,该模型可能已进入基准生态系统,但在此处提供的公开可见材料中没有附带完全透明的组织身份。如果你试图验证供应商的责任,匿名提交需要格外谨慎。
第四,有影响者评论。笔记中提到多位影响者发帖称该团队是张迪的淘天集团未来生活实验室。这对于模式识别很有用,因为重复的说法通常会揭示谣言集群的形成地点。但社交平台上的重复并不能将说法变成证据。
如何解读匿名模型提交
匿名提交很重要,因为它改变了验证的负担。对于买家而言,它影响采购和风险审查:你不能假设列出的名称与可以签署企业条款的法律实体清晰对应。对于创作者而言,它影响商业信心:如果客户询问谁运营该模型,“网上的人认为它与阿里巴巴有关”并不是你可以依赖的答案。对于研究人员而言,它影响可复现性和问责制:模型可能在公开场合进行基准测试,而团队身份仍然模糊不清。
评估任何归属声明的实用方法是将其归入三个类别之一。原始证据包括官方公告、公司博客、模型卡、具名组织拥有的存储库、指明运营方的法律条款,或可识别发言人的直接声明。次级报道包括总结声明的文章、称模型为第一名的标题,以及引用未具名来源的评论。谣言包括没有出处的截图、不完整的片段、转发的声明以及相互引用的社交帖子。
这份清单是处理谁打造了 HappyHorse 团队之谜的最快方法,而不会陷入循环溯源。如果关于 HappyHorse 的说法以“人们说”开头,请将其归为谣言,直到你可以追溯到原始证据。
阿里巴巴、淘天集团和张迪:关于谁打造了 HappyHorse 团队的最有力线索

阿里巴巴和淘天集团的说法
现有材料中最有力的归属线索是阿里巴巴角度。一份题为《Could HappyHorse be Z-video in disguise, from Alibaba?》的报告称,HappyHorse-1.0 来自阿里巴巴的淘天集团。这是一个有意义的线索,因为它指向一个具体的、主要的集团部门,而不是模糊的初创公司谣言。如果属实,它将彻底改变人们评估该模型背景、工程深度和运营成熟度的方式。
但关键短语是如果属实。现有材料不包含该说法的原始证据。研究笔记中没有官方的阿里巴巴公告,没有公司拥有的存储库,没有阿里巴巴签署的模型卡,也没有直接的公司声明确认作者身份。因此,使用这份报告的正确方式是将其视为一个值得追踪的线索,而不是一个既定事实。
这就是重复的说法甚至可能误导经验丰富的开发者和运营者的地方。一旦一个来源将一个模型与一家知名公司联系起来,社交评论往往会将“据报道的关联”压缩为“已确认的所有者”。这种跳跃正是当前证据不支持的。如果你认真评估这一说法,请将每一次提及与原始工件进行比较:官方域名、具名法律运营方,或可追溯到组织本身的公开文档。
未来生活实验室的归属
第二个主要线索更具体,但也更脆弱。来自《Who Developed HappyHorse-1.0?》的一个片段说:“HappyHorse-1.0 背后的团队是张迪的淘天集团未来生活实验室(由 ATH-AI Innovation 打造……”问题是这个片段不完整。由于句子中断,它不能被视为一个完整、自足的确认。它是一个方向性线索,而不是最终的归属。
尽管如此,它仍然有价值,因为它与更广泛的淘天集团说法重叠。这种重叠正是比较不完善来源的方式。在现有材料中,一致的线索不是“已确认的阿里巴巴所有权”。一致的线索更窄:多个参考指向阿里巴巴的淘天集团或与淘天相关的内部实验室。这种一致性使线索比随机谣言更强,但它仍然没有达到验证的标准。
笔记中提到的影响者帖子符合相同的模式。据报道,多位影响者发帖称该团队是张迪的淘天集团未来生活实验室。仅将其用作模式匹配的信号。重复可以表明一个说法正在广泛传播,但它本身不能确立作者身份。要将该说法从“合理线索”升级为“已确认事实”,你需要阿里巴巴、淘天集团、实验室本身,或由该组织控制的文档化存储库或模型发布物的直接声明。
因此,在比较重叠的说法时,要寻找在不同来源中保持稳定的信息:淘天反复出现;阿里巴巴反复出现;未来生活实验室至少在一个片段和影响者的重复中出现。仍然需要验证的是,这些引用是否是官方的、当前的,并且与名为 HappyHorse-1.0 的确切模型相关联,而不是传闻中的关系或别名。
在将 HappyHorse 模型用于工作之前,如何验证谁打造了 HappyHorse 团队
实用的尽职调查清单
如果你正在考虑将 HappyHorse-1.0 用于实际工作,请在投入生产之前使用严格的验证流程。第一步:识别运营方。找到服务、API、存储库或下载页面背后的法律实体名称。如果模型被呈现为 open source ai video generation model,请验证发布者是具名组织还是匿名账户。第二步:查找官方文档。寻找明确声明作者身份的模型卡、技术报告、公司页面或官方公告。
第三步:确认服务条款和许可。这是许多团队在使用视频工具时容易出错的地方。如果发布暗示了 image to video open source model 或 open source transformer video model,请检查实际的许可文件和使用条款。“开放”品牌不足以说明问题。你需要管理商业使用、修改、再分发和托管服务运营的确切条款。对于客户工作,需要回答的问题基本上是:open source ai model license commercial use 的语言实际允许什么?
第四步:验证隐私和数据处理。如果提示、上传、参考图像或生成的视频通过托管服务,请检查运营方是否声明了保留期限、训练重用政策和删除控制。第五步:确认托管和支持细节。这是一个自托管版本、一个受限 API,还是一个没有公开部署文档的仅用于基准测试的条目?
当前研究中的尽职调查空白是显而易见的:没有经过验证的公司身份,没有确认的公开团队,也没有诸如 SLA、正常运行时间、支持级别或安全承诺等有来源的企业细节。这并不意味着模型不好。这意味着你还没有足够的经过验证的运营方信息来将其视为一个正常的企业供应商。
投入生产使用前需要回答的问题
在投入生产使用之前,请明确回答五个问题。谁合法运营该模型?商业权利是什么?模型托管在哪里?上传的资产会发生什么?如果结果失败或服务中断,存在哪些支持途径?如果这些答案缺失,请将模型保持在评估模式。
如果你正在评估任何 run ai video model locally 工作流程,也适用相同的清单。如果可以本地执行,请确认权重是否实际可用,许可是否允许推理,以及任何使用限制是否在本地部署后仍然有效。许多项目听起来很开放,直到你检查发布条款。
对于法律和采购审查,请保留一份简短清单:许可条款、商业使用权限、支持渠道、模型托管细节、具名运营方、隐私政策、数据保留声明,以及任何影响客户交付的赔偿或限制语言。如果这些项目甚至有一半缺失,你还没有看到一个生产就绪的采购包。
如果 HappyHorse 团队的构建者问题仍未解决,创作者和创始人应该怎么做

安全地将模型用于实验
如果作者身份问题仍未解决,明智的做法是将输出质量与供应商信任分开。你仍然可以在沙盒中测试运动质量、提示依从性、时间一致性和伪影率,而无需假设模型已为商业用途做好准备。这为你提供了有用的信号,同时将风险限制在一定范围内。对于实验,请使用非敏感提示,避免使用客户资产,并准确记录模型的访问来源以及当时可见的条款。
这种区分至关重要,因为现有研究仅验证了归属方面的不确定性。它不验证技术架构、定价、支持、许可,或 HappyHorse-1.0 是否以稳定的产品形式公开可用。因此,如果测试结果看起来很棒,请仅将其视为关于生成输出的证据,而不是关于合法可用性或运营方可靠性的证据。
实用的分阶段路径效果最好。从使用一次性或合成输入进行沙盒测试开始。记录界面、存储库或基准页面是否具名运营方。保存条款、许可文本和任何公开声明的截图。如果模型后来与商业工作相关,只有在你拥有可追溯的所有权和权利来源后,才能进行正式审查。
何时避免生产依赖
当所有权、数据政策和服务可靠性仍未验证时,请避免生产依赖。对于营销工作流程,这意味着不能仅凭排名声明做出客户交付承诺。一个模型可能备受关注,但仍然无法通过采购。如果你无法确定谁运营该服务、资产存储在哪里以及适用哪些商业权限,请不要将其作为营销流程中的依赖项。
对于评估增长工具的初创公司也一样。在将模型集成到自动化内容流之前,需要验证所有权、隐私语言、支持联系人和服务连续性细节。目前的笔记没有验证正常运行时间、SLA、企业支持、定价或许可。即使模型的输出非常出色,这也足以阻碍运营信任。
从现有研究中可以推断出的信息虽然有限但很有用:作者身份的不确定性是真实存在的,据报道存在匿名框架,以及与阿里巴巴/淘天相关的归属仍然是线索而非已确认的事实。无法推断出的是团队通常做出上线决策所需的一切:架构、部署模型、支持义务、定价和商业权利。
这就是为什么最安全的采用路径是分阶段的:首先是沙盒测试,其次是法律审查,只有在来源和权利验证后才进行有限部署,只有在运营方身份在原始来源中得到记录后才进行更广泛的推广。
HappyHorse-1.0 的背景:接下来要关注哪些关于开源AI视频生成模型的主张

确认团队的信号
确认开发者的证据是直截了当的。来自具名组织的官方公告即可。公司文档、经过验证的组织账户拥有的存储库、具名团队的模型卡,或来自阿里巴巴、淘天集团或其他声称拥有 HappyHorse-1.0 的特定公司的直接声明,也都可以。这些都是能将故事从“有强有力线索的谜团”转变为“已确认来源”的工件。
基准披露也会有所帮助。如果排行榜条目链接回官方发布页面、技术报告或有文档记录的提交者身份,那将弥补当前大部分归属空白。目前,据报道的匿名提交框架意味着基准可见性并不能自动解决作者身份问题。
这如何影响开源和本地使用兴趣
这个谜团很重要,因为它与人们已经在进行的精确搜索相交:open source ai video generation model、open source transformer video model、image to video open source model 和 run ai video model locally。HappyHorse-1.0 在这个领域引起了关注,但当前的研究并未确认它是否真正开源,权重是否可用,或者适用何种商业使用许可。即使是短语 happyhorse 1.0 ai video generation model open source transformer 也应被视为搜索模式,而非已确认的技术描述。
这意味着任何追踪本地使用或自托管可能性的人都应等待具体的工件:具名组织的官方存储库、可下载的权重、推理说明、硬件要求,以及明确授予预期权利的许可文件。没有这些部分,一个模型可能在基准测试中闻名,但对于实际的本地工作流程或客户工作仍然无法使用。
一份可靠的监控清单可以简化这一点。关注:具名组织下的官方存储库、许可文件、模型卡、包含方法的基准披露、列出项目的组织页面、具名运营方的法律条款,以及来自可信分析师的独立验证,这些分析师会链接回原始证据。如果未来的公告通过官方文档将 HappyHorse-1.0 直接与阿里巴巴的淘天集团或张迪的未来生活实验室联系起来,那将实质性地改变风险状况。
目前,最准确的答案仍然是最不引人注目的。HappyHorse-1.0 正被热议为一款顶级AI视频模型,但其团队在现有材料中仍未公开确认。阿里巴巴、淘天集团和未来生活实验室的归属是关于谁打造了 HappyHorse 团队的最有力线索,但在原始证据出现之前,它们仍然只是线索。如果你正在认真评估该模型,请将基准热度与运营方信任分开对待,并在任何生产使用之前验证所有权、权利、托管和数据处理。